Background
Tidy Tuesday
This is my first published of hopefully many Tidy Tuesday analysis posts. Tidy Tuesday is a weekly social data project in the R for Data Science community where R users explore a new dataset and share their findings. If you’re an R user (or aspiring) I highly recommend participating. A few specific Tidy Tuesday resources I’d recommend are David Robinson’s Tidy Tuesday screen casts, Twitter #TidyTuesday, and the TidyTuesday podcast with Jon Harmon. All Tidy Tuesday datasets are available on Github.
The Great American Beer Festival
This Tidy Tuesday, we’re analyzing data from The Great American Beer Festival. The Great American Beer Festival (GABF) is a three-day annual festival in Denver, Colorado. Judges evaluate several thousand beers entered by hundreds of breweries and award gold, silver, and bronze medals in 100+ categories - though not every medal is necessarily awarded in each category. GABF was founded in 1982 and had 22 participating breweries in the first year. To download the data I use the tidytuesdayR package.
Analysis
The GABF data set has an observation (row) for each beer that received an award for each year it received one. The obvious challenge with that is the dataset only includes beers awarded - it provides no data regarding participation. Without participation data many questions will go unanswered. We can’t infer the overall quality of beers based on total awards because we won’t know how many times they didn’t win. Huge bummer because many of the questions that came to mind when I saw the name of the dataset won’t be possible, c’est la vie.
I summarized the data set with skimr. The output allowed me to quickly get an understanding of the dataset and identify some data cleaning tasks. The data types of the columns are all character, except year which is double. I converted medal to factor so I could more easily analyze it as an ordinal attribute. State has 52 unique values, but I spotted duplicate records due to casing (AK & Ak and WA & wa). I changed the casing in these observations bringing the number of states to 50, including Washington D.C. meaning one state has no awards. Medal is a character which makes sense, but I added a numeric version in case I want to do some weighted totals.
| Name | gabf |
| Number of rows | 4970 |
| Number of columns | 7 |
| _______________________ | |
| Column type frequency: | |
| character | 6 |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| medal | 0 | 1 | 4 | 6 | 0 | 3 | 0 |
| beer_name | 0 | 1 | 2 | 89 | 0 | 3811 | 0 |
| brewery | 0 | 1 | 6 | 58 | 0 | 1859 | 0 |
| city | 0 | 1 | 3 | 44 | 0 | 803 | 0 |
| state | 0 | 1 | 2 | 2 | 0 | 52 | 0 |
| category | 0 | 1 | 4 | 76 | 0 | 515 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| year | 0 | 1 | 2007.88 | 8.68 | 1987 | 2002 | 2009 | 2015 | 2020 | ▂▃▅▆▇ |
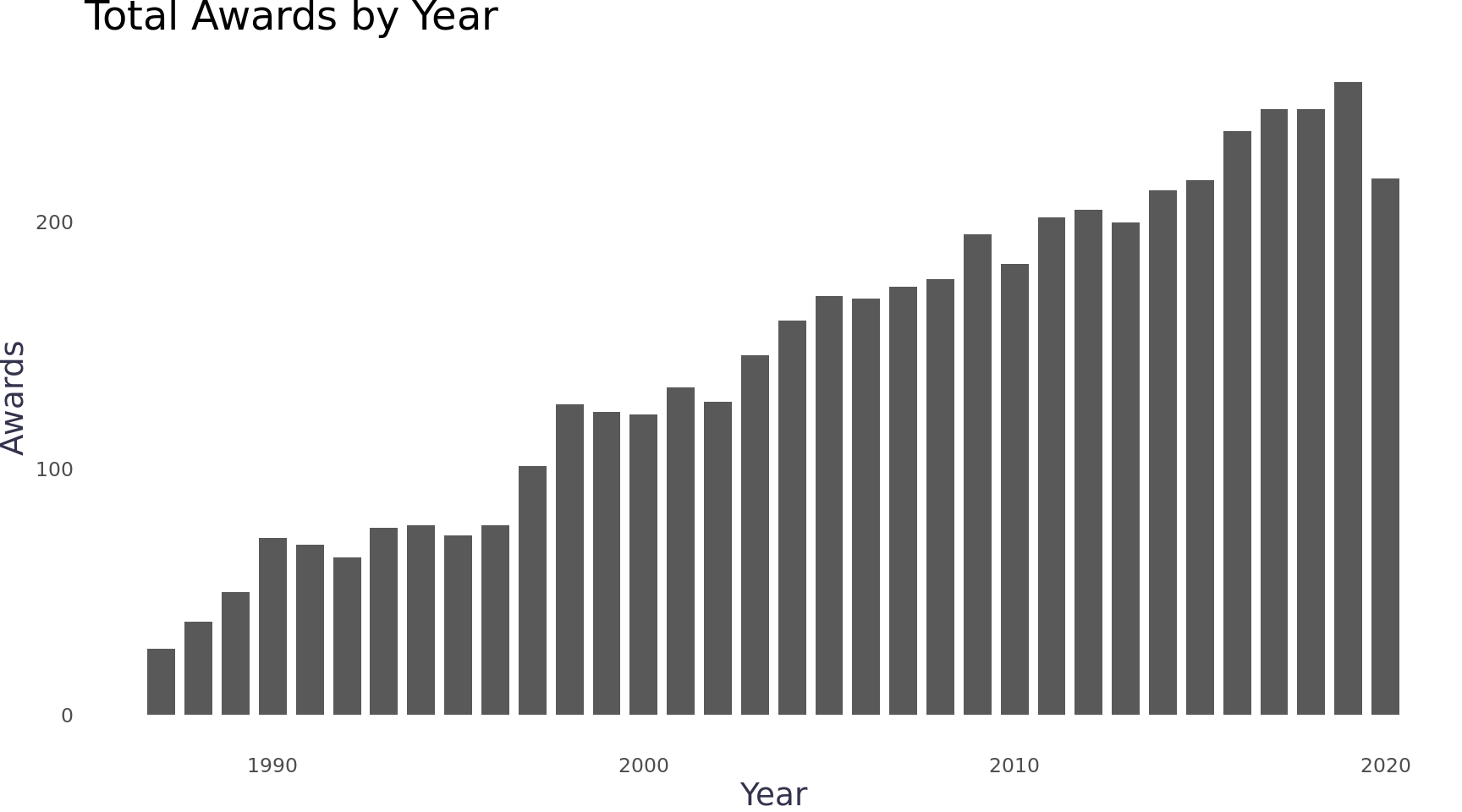
I visualized awards over time and saw the dataset starts in 1987 (27 awards) and ends in 2020 (218 awards). Growth appears to be linear with only a few years that ever decreased.
Code
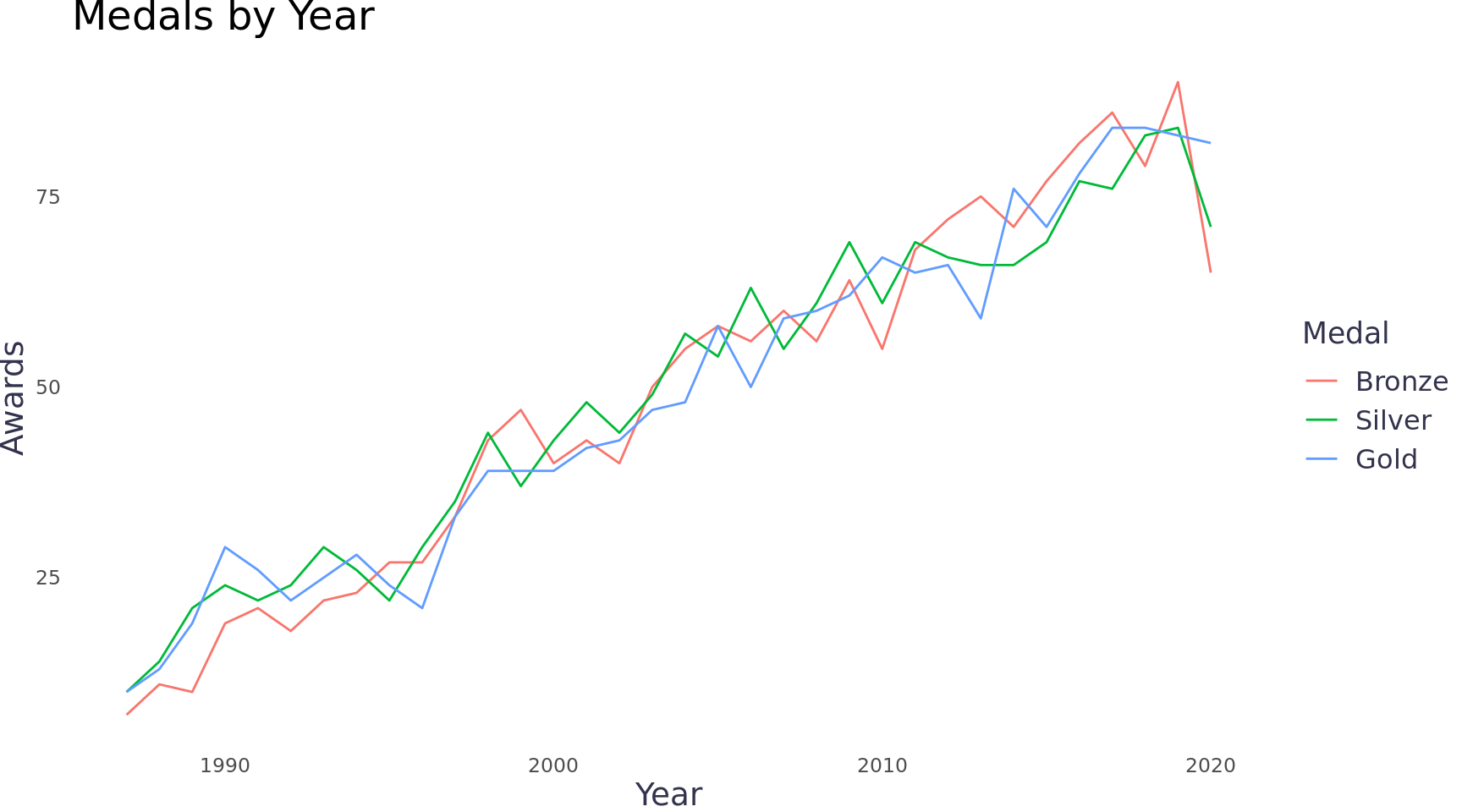
The annual growth in the number of awards appears to be similar for each medal class.
Code
The dataset has 515 different award categories, which appear to be different categories of beer. That’s more than I expected. Looking at the top 5 categories table, the category with the most awards is the Classic Irish-Style Dry Stout with 62. That accounts for 0.01 percent of the awards and less than two awards per year - meaning there aren’t categories that have been used throughout the 34 years. Given that, the category attribute will be difficult to use because it’s probably very inconsistent year to year.
Top 5 Beer Categories
Code
cats <- gabf %>%
mutate(category = forcats::fct_lump(category, n = 5)) %>%
group_by(category) %>%
tally()
other_cat <- cats %>%
filter(category == "Other")
cats %>%
filter(category != "Other") %>%
arrange(dplyr::desc(n)) %>%
bind_rows(., other_cat) %>%
kableExtra::kable(col.names = c("Category", "Awards")) %>%
kableExtra::kable_styling(bootstrap_options = "hover") | Category | Awards |
|---|---|
| Classic Irish-Style Dry Stout | 62 |
| American-Style Pale Ale | 61 |
| Bock | 61 |
| Robust Porter | 61 |
| Imperial Stout | 60 |
| Other | 4665 |
The other attributes in my summary table (beer_name, brewery, and city) all appear to be formatted correctly, but quite disperse I won’t inspect them any further at the moment.
State is one attribute that seemed clean so I decided to take a closer look at that. The top 5 states account for almost 50 percent of all the awards. Two of the top five states are California and Texas, which are the two most populous states in the US.
Top 5 States
Code
states <- gabf %>%
mutate(state = forcats::fct_lump(state, n = 5)) %>%
group_by(state) %>%
tally()
others <- states %>%
filter(state == "Other")
states %>%
filter(state != "Other") %>%
arrange(dplyr::desc(n)) %>%
bind_rows(., others) %>%
kableExtra::kable(col.names = c("State", "Awards")) %>%
kableExtra::kable_styling(bootstrap_options = "hover")| State | Awards |
|---|---|
| CA | 962 |
| CO | 659 |
| OR | 328 |
| TX | 249 |
| WI | 234 |
| Other | 2538 |
Analyzing the states effectively will require population data to control for or consider per capita. Any mapping will require some sort of GIS data. These attributes are often packaged together because they’re used together frequently. There are a number of R libraries we can use. The most robust one I know off hand is tidycensus, which is a wrapper around the US Census Bureau’s API. I mention it for reference, but for simplicity I used albersusa. It has simple features which is the GIS data used by R’s sf package.
Joining albersusa data
The albersusa usa_sf() function pulls a state dataset from the package which includes population and simple features. I wrote a function that takes a data frame, which I can reuse easily. I know I’ll likely make more changes to gabf and changes after my awards_by_state function runs so create an ephemeral function just makes it a bit easier than managing multiple versions of data frames in my experience. I added some state level measurements that I assume we’d use later.
Code
awards_by_state <- . %>%
group_by(state) %>%
summarise(state_total_awards = n(),
state_total_awards_weighted = sum(medal_numeric),
state_years_with_awards = n_distinct(year)) %>%
ungroup() %>%
right_join(tigris::shift_geometry(albersusa::usa_sf("laea")), by = c("state"="iso_3166_2")) %>%
rename("state_name"="name") %>%
mutate(state_avg_award = state_total_awards_weighted / state_total_awards,
state_total_awards_per_cap = (state_total_awards / pop_2014) *100000,
state_percent_total_awards = state_total_awards / sum(state_total_awards, na.rm = T)) %>%
replace_na(list(state_total_awards = 0, state_total_awards_weighted = 0, avg_award = 0, state_total_awards_per_cap = 0, state_percent_total_awards = 0, state_years_with_awards = 0)) State Rankings Table
I wanted to view the state data with the populations and the new measures. I used a table view and some row-wise summaries to get more context for the top states and bottom states. I used the reactable pacakge because I could visualize row-wise summaries. It’s a lot of code, but most of it is pretty simple to adjust - I worked off of the package’s Twitter Followers demo and Women’s World Cup Predictions demo.
The table shows each state’s population, share of total awards, awards per capita (PC), and the average medal (Avg). The table is sorted by the awards per capita (PC). The table provides a few new insights. A few low population states (e.g. Wyoming, Alaska, & Delaware) have a disproportionate number of awards. Alternatively, a few high population states are not well represented including New York, Georgia, and most of all Florida (no shock). Most states have a centered distribution of medals (average silver) with the exceptions mostly being states that have a sparse number of awards.
Code
make_color_pal <- function(colors, bias = 1) {
get_color <- colorRamp(colors, bias = bias)
function(x) rgb(get_color(x), maxColorValue = 255)
}
off_rating_color <- make_color_pal(c("#f93014", "#f8fcf8", "#4DBE56"), bias = 1.3)
rating_column <- function(maxWidth = 55, ...) {
colDef(maxWidth = maxWidth, align = "center", class = "cell number", ...)
}
tbl <- gabf %>%
awards_by_state() %>%
select(state_name, pop_2014, state_percent_total_awards, state_total_awards_per_cap, state_avg_award) %>%
reactable(
height = 550,
striped = TRUE,
defaultPageSize = 51,
defaultSorted = "state_total_awards_per_cap",
defaultColDef = colDef(headerClass = "reactable-header", align = "left"),
columns = list(
state_name = colDef(
name = "State",
width = 150
),
pop_2014 = colDef(
name = "Population (2014)",
cell = function(value) {
width <- paste0(value * 100 / max(.$pop_2014), "%")
value <- format(value, big.mark = ",")
value <- format(value, width = 14, justify = "right")
bar <- div(
class = "reactable-bar-chart",
style = list(marginRight = "6px"),
div(class = "reactable-bar", style = list(width = width, backgroundColor = "#3fc1c9"))
)
div(class = "reactable-bar-cell", span(class = "reactable-number", value), bar)
}
),
state_percent_total_awards = colDef(
name = "Percent of Total Awards",
cell = JS("function(cellInfo) {
// Format as percentage
const pct = (cellInfo.value * 100).toFixed(1) + '%'
// Pad single-digit numbers
let value = pct.padStart(5)
// Render bar chart
return (
'<div class=\"reactable-bar-cell\">' +
'<span class=\"reactable-number\">' + value + '</span>' +
'<div class=\"reactable-bar-chart\" style=\"background-color: #e1e1e1\">' +
'<div class=\"reactable-bar\" style=\"width: ' + pct + '; background-color: #fc5185\"></div>' +
'</div>' +
'</div>'
)
}"),
html = TRUE
),
state_total_awards_per_cap = rating_column(
name = "PC",
defaultSortOrder = "desc",
cell = function(value) {
scaled <- (value - min(.$state_total_awards_per_cap)) / (max(.$state_total_awards_per_cap) - min(.$state_total_awards_per_cap))
color <- off_rating_color(scaled)
value <- format(round(value, 1), nsmall = 1)
div(class = "reactable-per-capita", style = list(background = color), value)}
),
state_avg_award = rating_column(
name = "Avg",
cell = function(value) format(round(value, digits = 2), nsmall = 2)
)
),
compact = TRUE,
class = "reactable-tbl")
div(class = "reactable-tbl-view",
div(class = "div-subtitle",
div(class = "div-title", "Total GABF Awards by State, Population Adjusted (1987 - 2020)"),
"When reviewing total awards received per capita, Colorado, Wyoming, Alaska, Oregon, & Montana look like the big winners"
),
tbl
)Colorado is a great state for beer, but I would not expect it to be distinguished as a clear leader among the states. Similar story with Wyoming. Again, the data set does not provide information regarding participation. I suspect there is skew in the number of awards won by state because the festival is always held in Denver. Breweries located closer to Denver are more likely to participate.
Separately, time obviously plays a significant role that is not captured by the above table. The festival is older than most of the breweries that participated in 2020. The competition in 2020 was probably completely different, more crowded, than it was in 1987. When looking at total awards, we’re not accounting for that.
Brief USA Beer History
A little history on brewing in the US helps us better understand the time variable in the absencense of participation data. Jimmy Carter signed HR 1337 into law which made it explicitly legal to homebrew beer. When that law was passed, there were only ~50 breweries in the USA. Today, there are ~7k permitted breweries. You can read more in this interesting article on Vinepair. With that in mind, when the festival started breweries like Anheuser-Busch, Miller Brewing Company, and Coors Brewing Company controlled even more of the market share than they do today. The newcomers at that time were Boston Beer Company (i.e. Sam Adams) and Alaskan Brewing Co., founded in 1984 and 1986 respectively. That history plays a significant role in our analysis because the newer breweries of today are years behind these older breweries with regard to winning awards. 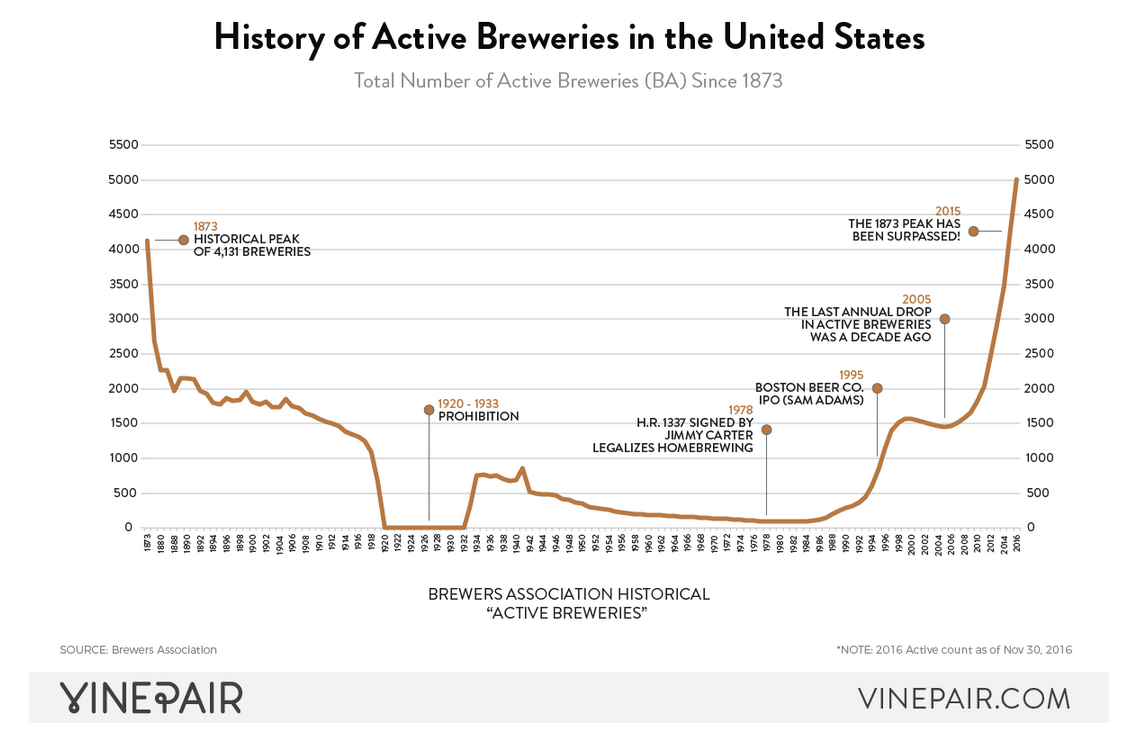
Animated Map
I visualized the award data in a Choropleth map. To capture the year data, I used gganimate to loop through and create a map for each year in a gif. To scale the color of the Choropleth by the specific year, rather than by the entire 34 years, I updated the awards_by_state function to include year (awards_by_state_year). It’s a bit of code to calculate different sums and counts for each level of aggregation and to impute records for missing years, but dplyr and tidyr do the heavy lifting. Nesting the annual observations in a data frame column keeps the data frame at 51 rows and prevents duplicating the simple features data for each year. The ggplot aesthetics will not take the nested data, but it’s easier to work with the data frame that way for other purposes and the function will probably be handy later. Below is the function spelled out.
Code
# Creates a column with the year total, every row with the same year has the same value
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards")
# Aggregates by year, state, and year total and counts the number of rows
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards") %>%
group_by(state, year, year_total_awards) %>%
summarise(state_year_total_awards = n()) %>%
ungroup()
# Joins missing states (from state.abb) and imputes the missing years and zero awards for each
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards") %>%
group_by(state, year, year_total_awards) %>%
summarise(state_year_total_awards = n()) %>%
ungroup() %>%
full_join(tibble(state = state.abb), by = c("state" = "state")) %>%
replace_na(list(year = 1987)) %>%
complete(state, nesting(year)) %>%
replace_na(list(state_year_total_awards = 0))
# Imputes year_total_awards for the new years that were imputed in the last step
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards") %>%
group_by(state, year, year_total_awards) %>%
summarise(state_year_total_awards = n()) %>%
ungroup() %>%
full_join(tibble(state = state.abb), by = c("state" = "state")) %>%
replace_na(list(year = 1987)) %>%
complete(state, nesting(year)) %>%
replace_na(list(state_year_total_awards = 0)) %>%
group_by(year) %>%
mutate(year_total_awards = max(year_total_awards, na.rm = T)) %>%
ungroup()
# Calculate the percent of year total for each record (Choropleth fill)
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards") %>%
group_by(state, year, year_total_awards) %>%
summarise(state_year_total_awards = n()) %>%
ungroup() %>%
full_join(tibble(state = state.abb), by = c("state" = "state")) %>%
replace_na(list(year = 1987)) %>%
complete(state, nesting(year)) %>%
replace_na(list(state_year_total_awards = 0)) %>%
group_by(year) %>%
mutate(year_total_awards = max(year_total_awards, na.rm = T)) %>%
ungroup() %>%
mutate(pct_of_year_total_awards = state_year_total_awards / year_total_awards)
# Finally, nest the yearly data under the state and join the albersusa data set and create the function
awards_by_state_year <- . %>%
add_count(year, name = "year_total_awards") %>%
group_by(state, year, year_total_awards) %>%
summarise(state_year_total_awards = n()) %>%
ungroup() %>%
full_join(tibble(state = state.abb), by = c("state" = "state")) %>%
replace_na(list(year = 1987)) %>%
complete(state, nesting(year)) %>%
replace_na(list(state_year_total_awards = 0)) %>%
group_by(year) %>%
mutate(year_total_awards = max(year_total_awards, na.rm = T)) %>%
ungroup() %>%
mutate(pct_of_year_total_awards = state_year_total_awards / year_total_awards) %>%
group_by(state) %>%
nest() %>%
right_join(tigris::shift_geometry(albersusa::usa_sf("laea")), by = c("state"="iso_3166_2"))Then we can plug the function and pipeline the data frame through and into a gganimate output.
Code
chorpleth <- gabf %>%
awards_by_state_year() %>%
unnest(data) %>%
ggplot(ggplot2::aes(geometry = geometry, fill = pct_of_year_total_awards, group = year)) +
geom_sf() +
scale_fill_viridis_c(option = "magma", alpha = .9, begin = .1, labels = scales::percent) +
labs(title = 'Percent of Total Awards by State, Year: {round(frame_time,0)}', fill = "Awards") +
theme_blog(axis.text = ggplot2::element_blank(),
axis.ticks = ggplot2::element_blank()) +
transition_time(year) +
ease_aes('linear')
animate(chorpleth, fps = 5)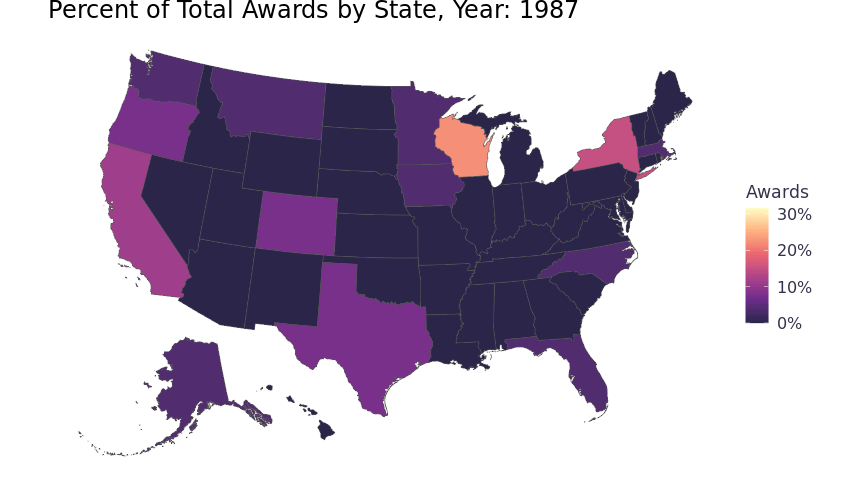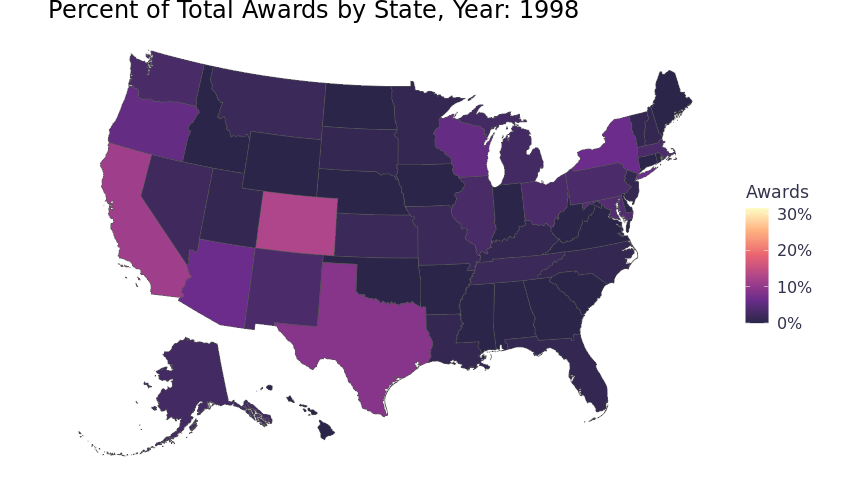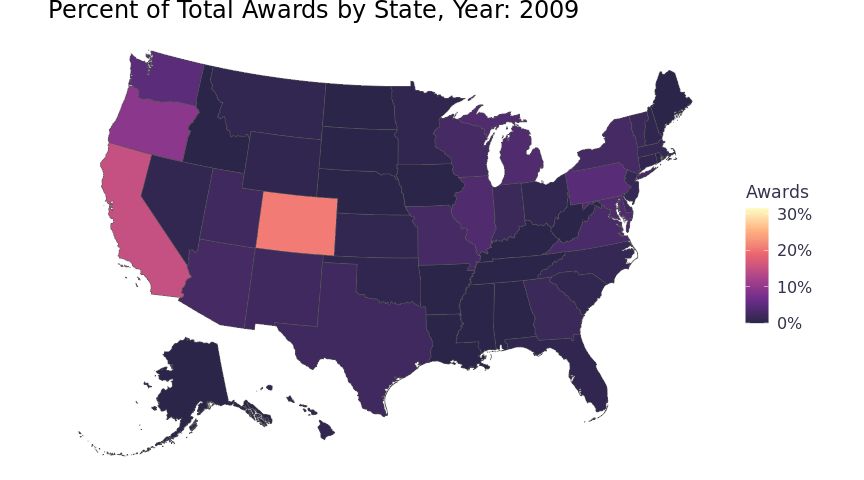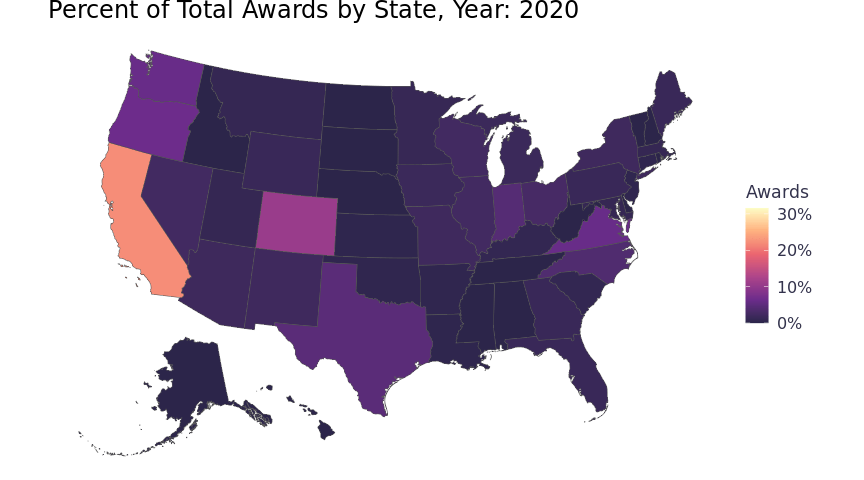
Interactive TIE Fighter Plot & Line Chart
Looking at the animation, you can see Wisconsin has lost a proportion of total awards over the 34 years. This view does not provide clarity regarding where those proportions are going. To see the trend of awards for the state, I visualized a logistic regression model in a TIE fighter plot. A logistic regression model provides a useful summary for the 34 years of awards for each state, but I wanted to keep the annual context so I thought the TIE fighter plot would work better accompanied with a line chart. I decided to add in dynamic highlighting so that both visuals can be used interactively. I used crosstalk and plotly to build in the interactivity. Crosstalk enables htmlwidgets with cross-widget interactions (highlighting and filtering). Plotly builds interactive graphs and the author wrote a ggplotly() function that will convert ggplot2 graphics to plotly, brilliant! Now I can build interactive data visualizations without knowing much more than ggplot.

I used a number of resources to figure out how to do this. David Robinson wrote intro to broom, which covers all the needed tools to build TIE fighter plots and more. Carson Servert wrote a plotly book which covers all plotly functionality with examples. Plotly mostly handles crosstalk for the user, but I have found it easier to learn crosstalk to know what’s happening under the hood. Crosstalk relies on it’s SharedData object. Carson’s book also has a client-side linking chapter which talks through how to use crosstalk in plotly. Finally, this Stackoverflow post also provided a quick, repeatable example.
The widgets need two SharedData objects from gabf to cross-link the visuals. One with an observation for each state and the years and awards nested as a tibble column (TIE fighter plot). One with an observation for each state for each year with awards won (line chart). The ephemeral functions now come in handy. I can join my state level awards data with my state & year level awards data in order to filter out states with that didn’t receive awards in more than one year and states that didn’t receive more than five total awards for both SharedData objects. Below are the two SharedData objects spelled out.
Code
###################
# TIE Fighter Data
###################
# Filter states without enough awards and remove simple features (not needed and they are heavy)
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5)
# Create a model for each state
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
mutate(model = map(data, ~ glm(cbind(state_year_total_awards, year_total_awards - state_year_total_awards) ~ year, data = .x , family = "binomial")))
# Tidy model data
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
mutate(model = map(data, ~ glm(cbind(state_year_total_awards, year_total_awards - state_year_total_awards) ~ year, data = .x , family = "binomial"))) %>%
mutate(results = map(model, broom::tidy, conf.int = TRUE)) %>%
unnest(results) %>%
ungroup() %>%
filter(term == "year")
# Reorder the data by estimate (states listed by trend)
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
mutate(model = map(data, ~ glm(cbind(state_year_total_awards, year_total_awards - state_year_total_awards) ~ year, data = .x , family = "binomial"))) %>%
mutate(results = map(model, broom::tidy, conf.int = TRUE)) %>%
unnest(results) %>%
ungroup() %>%
filter(term == "year") %>%
mutate(state = fct_reorder(state, estimate))
# Add attributes for plot formatting and tooltip
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
mutate(model = map(data, ~ glm(cbind(state_year_total_awards, year_total_awards - state_year_total_awards) ~ year, data = .x , family = "binomial"))) %>%
mutate(results = map(model, broom::tidy, conf.int = TRUE)) %>%
unnest(results) %>%
ungroup() %>%
filter(term == "year") %>%
mutate(state = fct_reorder(state, estimate)) %>%
mutate(p_value = case_when(
p.value >= .075 ~ "not confident",
p.value >= .025 ~ "somewhat confident",
p.value < .025 ~ "confident"),
trend = case_when(
estimate >= .0025 ~ "trending up",
estimate < -.0025 ~ "trending down",
T ~ "flat"
)) %>%
mutate(p_value = fct_relevel(p_value, c("not confident", "somewhat confident")))
# Create the SharedData object
tie_fighter_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
mutate(model = map(data, ~ glm(cbind(state_year_total_awards, year_total_awards - state_year_total_awards) ~ year, data = .x , family = "binomial"))) %>%
mutate(results = map(model, broom::tidy, conf.int = TRUE)) %>%
unnest(results) %>%
ungroup() %>%
filter(term == "year") %>%
mutate(state = fct_reorder(state, estimate)) %>%
mutate(p_value = case_when(
p.value >= .075 ~ "not confident",
p.value >= .025 ~ "somewhat confident",
p.value < .025 ~ "confident"),
trend = case_when(
estimate >= .0025 ~ "trending up",
estimate < -.0025 ~ "trending down",
T ~ "flat")) %>%
mutate(p_value = fct_relevel(p_value, c("not confident", "somewhat confident"))) %>%
SharedData$new(key = ~state_name, group = "Choose states (hold shift to select multiple):")
###################
# Line Chart Data
###################
# Filter states without enough awards and remove simple features (not needed and they are heavy)
line_chart_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5)
# Unnest the annual observations for ggplot aesthetics
line_chart_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
unnest(data)
# Create the SharedData object
line_chart_data <- . %>%
awards_by_state_year() %>%
left_join(y = gabf %>% awards_by_state()) %>%
select(-geometry) %>%
filter(state_years_with_awards > 1 & state_total_awards > 5) %>%
unnest(data) %>%
SharedData$new(key = ~state_name, group = "Choose states (hold shift to select multiple):")Again just use the functions in a pipeline into ggplot and pass the ggplot objects to ggplotly. Most of the ggplot code is straight forward if you’re a ggplot user, but the text aesthetic is a bit of a blob. That’s because ggplotly allows aesthetics to be set in the tool tip using tooltip = "text". So if you paste together data and html tags you can build a nice tool tip. It’s tedious, but useful. Finally, subplot ties the plots together in a view with highlighting. Just a heads up - if you use htmlwidgets in a blogdown site, css classes can start bumping into another. Objects can disappear simply because the css container is smaller the the htmlwidget, use your browser tools to reset sizing and debug.
Code
greys <- brewer.pal(n = 9, "Greys")
greys <- c(greys[3], greys[6], greys[9])
tie_fighter_plot <- gabf %>%
tie_fighter_data() %>%
ggplot(aes(x = estimate, y = state, key = state_name, group = state_total_awards, color = p_value,
text = paste0("<b>", state_name, "</b>\n", if_else(p_value == 'confident', glue('P-Value: {format(round(p.value, digits = 4), nsmall = 4)}\nThe number of {state_name} awards is definitely {trend}.'),
if_else(p_value == 'somewhat confident', glue::glue("'P-Value: {format(round(p.value, digits = 4), nsmall = 4)}\nThe number of {state_name} awards is {trend}, but there is some uncertainty."), glue::glue("P-Value: {format(round(p.value, digits = 4), nsmall = 4)}\nThe number of {state_name} awards appears to be {trend}, but there is signficant uncertainty."))))),
guides = guides(color = NULL)) +
geom_point(size = 1.75) +
geom_errorbarh(aes(
xmin = conf.low,
xmax = conf.high),
height = .5,
size = 1,
show.legend = FALSE) +
geom_vline(xintercept = 0, lty = 2, color = "#a0aace") +
scale_colour_manual(values = greys) +
scale_x_continuous(limits = c(-0.15, 0.15),
breaks = c(-.1, 0, .1),
labels = c("Descreasing", "", "Increasing")) +
labs(
x = "Trend",
title = NULL,
y = NULL,
color = NULL) +
theme_blog()
tie_fighter_plot <- plotly::ggplotly(tie_fighter_plot, tooltip = "text", height = 625)
line_chart <- gabf %>%
line_chart_data() %>%
ggplot(aes(x = year, y = state_year_total_awards, key = state_name, group = state_total_awards,
text = glue::glue("<b>{state_name} Awards</b>\n{state_year_total_awards} ({year})\n{state_total_awards} (1987-2020)\n"))) +
geom_line() +
labs(
x = "Year",
title = NULL,
y = "") +
theme_blog(panel.grid.major.y = element_blank())
line_chart <- ggplotly(line_chart, tooltip = "text", height = 625)
linked_plots <- subplot(tie_fighter_plot,
line_chart,
widths = c(.35, .65)) %>%
layout(showlegend = FALSE) %>%
highlight(on = "plotly_click", selectize = TRUE, dynamic = T)
div(class = "subplot-view",
div(class = "div-subtitle",
div(class = "div-title", "State Trends"),
"Alaska & Wisconsin are losing their share of awards to North Carolina, Indiana, & Virginia with South Carolina Jumping in the mix. California, Oregon, & Colorado appear to be maintaining their hold on the lion's share of the awards."
),
linked_plots
)Looking at the results (State Trends), the TIE fighter plot (on the left) shows the model results by state. The states with points further to the right are seeing an upward trend in the number of awards received, states to the left are seeing a downward trend. The lines (error bars) show the confidence intervals of the model. Darker colored TIE fighter’s have higher p-values (more certainty). The line chart (on the right) shows each state with the number of awards over the 34 years. Hover on a TIE fighter or line, the hover-link provides helpful text. Highlight any state by clicking on its TIE fighter or line, or just type the state in the search bar at the top. Multi-select states with shift, but it’s a bit shifty (pun intended). When selecting multiple states, change the brush color to make it easier to see which state is which.
Brewery, Category, & Beer Table
Our logistic regression model provides a great understanding of how states are preforming, what about breweries or beers? This is where the data set starts to get dirty, I’ll walk through a few of the issues using the first record in the table below (Beer Name == "Oktoberfest"). There are duplicate beer names across breweries. For example, there are 18 beers called Oktoberfest, which won 20 total medals. Since they aren’t unique, the data would need to be grouped on another attribute. Brewery would be the obvious choice, but drill down into the nested table and you will quickly spot duplicated brewery names with slight spelling variations (e.g. Stoudts Brewing Co. and Stoudt's Brewing Co.). This is pervasive upon inspecting other examples. The category on the other hand seems to have evolved rapidly or beers can enter multiple categories. The Oktoberfest beers have 10 different categories and Stoudt’s Oktoberfest (which is the exact same beer) has competed in two different categories. Categories also have some character issues, for example (the German-Style MC3=A4rzen is German-Style Mäerzen, the ä causes the characters). I can clean those up, but it’d be a bit of work.
Code
tbl <- gabf %>%
count(beer_name, brewery, category, medal) %>%
mutate(beer_name = fct_reorder(beer_name, n, sum)) %>%
pivot_wider(names_from = medal, values_from = n, values_fill = 0) %>%
mutate(total_medals = Gold+Silver+Bronze) %>%
clean_names("title") %>%
reactable(groupBy = "Beer Name",
defaultPageSize = 5,
filterable = TRUE,
searchable = TRUE,
defaultSorted = c("Total Medals"),
defaultSortOrder = "desc",
showPageSizeOptions = TRUE,
class = "reactable-tbl",
defaultColDef = colDef(aggregate = "sum", headerClass = "reactable-header", align = "left"),
compact = TRUE,
columns = list(
Brewery = colDef(
name = "Breweries",
aggregate = JS("
function(values, rows)
{
let breweries = values.filter((e, i) => values.indexOf(e) === i);
if(breweries.length > 1){
var left = '(';
var right = ')';
return breweries.length;
} else {
return breweries;
}
}")
),
Category = colDef(
name = "Categories",
aggregate = JS("
function(values, rows)
{
let categories = values.filter((e, i) => values.indexOf(e) === i);
if(categories.length > 1){
return categories.length;
} else {
return categories;
}
}")
),
`Category Total` = colDef(
aggregate = "max"
),
Gold = colDef(
name = "Total Golds"
),
Silver = colDef(
name = "Total Silvers"
),
Bronze = colDef(
name = "Total Bronzes"
)))
div(class = "reactable-tbl-view",
div(class = "div-subtitle",
div(class = "div-title", "All GABF Award Winning Beers "),
"Data is nested on beers, exploring the data shows a number of data cleaning activities required"
),
tbl
)Award Winning Categories by State
Cleaning up some of the text data would be cumbersome and I don’t want to invest all that additional time at this point. Given that, I’m going to focus on getting insights from the category data. Although it’s shifted a lot over the years, it seems to be the cleanest by far. The tidylo package can measure the which categories are most likely to get an award by state even and it deals with the different states have different numbers of awards. I recommend Julia & Tyler’s article on the package site if you want to learn more.
The visual below shows which categories are most likely to get an award by state (bars that go to the right) and which categories are least likely (bars that go to the left) based on the historical data. I’m a big fan of stouts, porters, and sours which tend to be hard to find in certain states. Wisconsin and Illinois being less represented in those categories makes a lot of sense given all the love they give to German beer.
Code
gabf %>%
filter(fct_lump(state, 9) != "Other",
fct_lump(category, 7) != "Other") %>%
count(state, category) %>%
complete(state, category, fill = list(n = 0)) %>%
bind_log_odds(state, category, n) %>%
mutate(category = reorder_within(category, log_odds_weighted, state),
state = fct_reorder(state, -n)) %>%
arrange(desc(n)) %>%
ggplot(aes(log_odds_weighted, category)) +
geom_col() +
labs(title = "Most Award Winning Categories by State", x = NULL, y = "Category") +
scale_y_reordered() +
facet_wrap(~state, scales = "free_y", nrow = 3) +
theme_blog_facet(axis.text.x = element_blank(), axis.ticks.x = element_blank())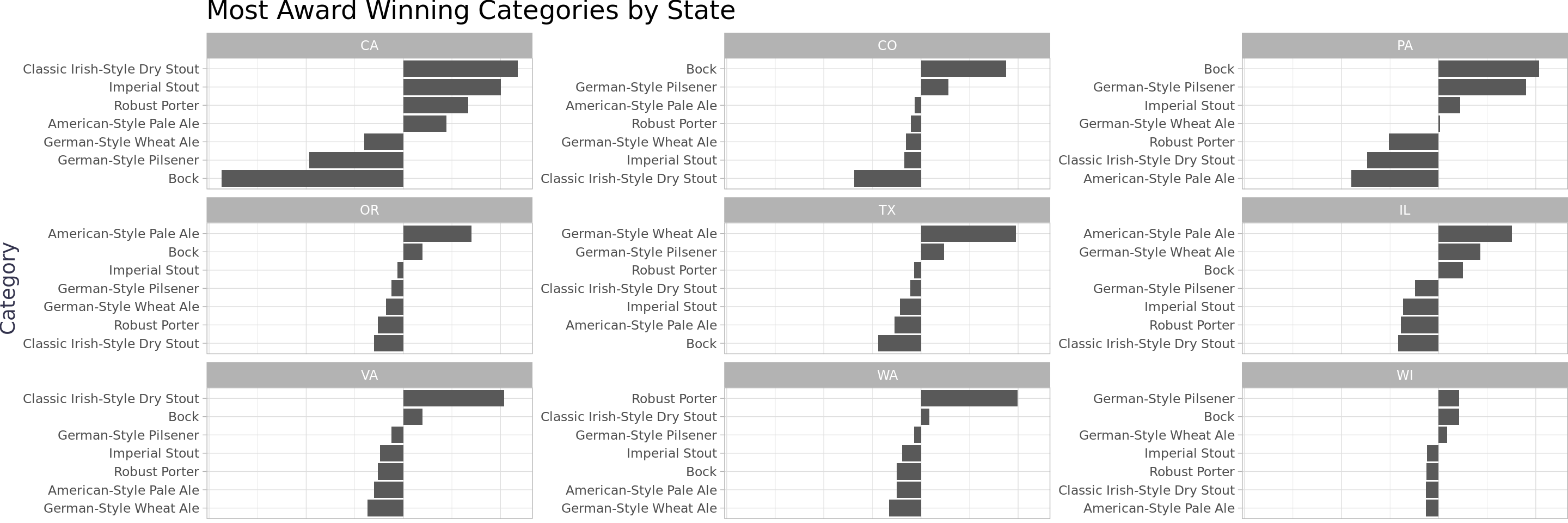
Wrapping Up
This data set would have been a lot more interesting if we had the full participation list. That being said, there were some interesting findings.
I went down a few rabbit holes that I did not write-up. I built a sunburst of the year, brewery, category, and beers just to explore the data more easily, but it was too difficult to read even after applying factor lumping - the data is just too disperse (i.e. too many unique values for each category). In order to make the sunburst usable I thought it would be helpful to build another cross-widget interaction to navigate the first few categories so they could be left off of the sunburst, but but it turns out sunburstR does not support crosstalk at the moment (side note, if you have not used sunburstR it makes beautiful d3.js sunbursts with very little effort). I had a quick conversation with one of the package maintainers and it sounds like it would be a significant effort to add that functionality - would be a super interesting project. I also tried to figure out how to clean up the character issues such as ä, but I couldn’t find any simple tools to use for that specific issue - would be interesting to research further.
Aside from those rabbit holes, the state rankings table provided interesting insights regarding awards per capita with Colorado way out in front. The TIE fighter plot showed that some lesser expected states including the Carolinas are catching up in the number of awards. The award winning categories by state log odds plot showed that, by in large, states win awards in different categories when comparing to each other.
Thanks for reading and if you have any feedback please do post it below or feel free to reach out to me directly (contact info is at the bottom)!