Code
List of 2
$ node:<externalptr>
$ doc :<externalptr>
- attr(*, "class")= chr [1:2] "xml_document" "xml_node"I had a web scraping walk through on my old blog where I scraped Airbnb to find listings with king size beds, but Airbnb did major updates to their site and the post wouldn’t render when I did an overhaul to my website so I no longer have it. I was trying to do a little scraping while I was doing some research and found myself wanting my guide so I started writing a new one while I was working - I’m coming back to it now to finish it up as a post. I’m not going to bother covering some of the basic web development skills necessary because I coincidentally cover most of that in the prerequisites for my post on building a blogdown site. So without further delay, let’s get to scraping!

R has a number of tools for scraping, but I typically only use rvest, RSelenium, and polite. The rvest library is the main one to know because it provides tools to extract (scrape) data from web pages. Often that’s all you need to web scrape. RSelenium allows you to drive web browsers from R, which is necessary when scraping some sites. Finely, polite implements a framework to use proper decorum when web scraping. I’ll very briefly cover polite in this post, but not extensively for reasons that will become clear later on.
When scraping, as is true with many things done it code, it’s easiest to start small. Scraping static sites that do not heavily rely on JavaScript to function is significantly less complicated than scraping sites that rely on JavaScript or dynamic sites. With that in mind, we’ll start with a very simple static site, the CRAN packages page, because it’s structured in a way that’s ideal for scraping so it’s straight forward.
The rvest package has a suite of tools for parsing the HTML document, which is the core functionality required to scrape. The first thing to do when scraping a page is to figure out what we want to scrape and determine it’s HTML structure. We can do this using the browser’s web developer tools, but most of this can also be done inside RStudio. It probably goes without saying if you look at the CRAN packages page, but I’d like to scrape the packages table and make it a data frame.

To inspect the page, we first read the page using read_html(). This reads the HTML page as is into our rsession for processing. We can see that the cran_packages_html object is a list of length two and both objects inside the list are external pointers. In other words, the cran_packages_html document is not in the active rsession, rather a pointer which directs R to the documents created by libxml2 which are stored in RAM (at least this is my rough understanding of how it works). For more information, Bob Rudis provided a very detailed response about scraping which touches on this point, but the take away should be that this object does not contain the data from the HTML page - just pointers!
List of 2
$ node:<externalptr>
$ doc :<externalptr>
- attr(*, "class")= chr [1:2] "xml_document" "xml_node"An aside, if you open cran_packages_html with viewer and trying to inspect one of the pointers, you’ll get an error could not find function "xml_child". That’s because rvest depends on xml2, but does not attached it to the global environment.
You can simply load xml2 to fix the issue.
The rvest package has a suite of functions for parsing the HTML document starting with functions that help use understand the structure including html_children() & html_name(). We can use html_children() to climb down the page and html_name() to see the tag names of the HTML elements we want to parse. For this page, we used html_chidren() to see that the page has a and a , which is pretty standard. We’ll want to scrape the <body> because that’s where the content of the page will be.
To further parse the <body>, we’ll use html_element() to clip the rest of the HTML document and look inside <body>. Within <body>, we can see there’s just a []](https://www.w3schools.com/tags/tag_div.asp).
We can continue the process with the <div> and we see an an and a . It’s fairly obvious we’ll want to the <table>, not <h1>, but just to illustrate if we look within <h1>, we’ll see no nodes exist beneath it.
character(0)That doesn’t mean <h1> has no data, it just means no HTML is a child of <h1>. Since <h1> a tag used on titles text), we can use [html_text()] to extract the actual text inside. This isn’t particularly useful in this case, but html_text() can be very useful.
[1] "Available CRAN Packages By Date of Publication"If we use html_element("table"), we can see it contains the data we’re looking for, but there’s a bit of HTML junk we’ll need to clean up for our data frame.
{html_node}
<table border="1">
[1] <tr>\n<th> Date </th> <th> Package </th> <th> Title </th> </tr>\n
[2] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/DrugSim2DR/ ...
[3] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/gmapsdistan ...
[4] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/actxps/inde ...
[5] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/AgroR/index ...
[6] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/aplot/index ...
[7] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/av/index.ht ...
[8] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/basemodels/ ...
[9] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bayesPop/in ...
[10] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/Bayesrel/in ...
[11] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/beanz/index ...
[12] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bookdown/in ...
[13] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bruceR/inde ...
[14] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/canvasXpres ...
[15] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CARBayes/in ...
[16] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/clinDR/inde ...
[17] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/cmm/index.h ...
[18] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/complexlm/i ...
[19] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CPC/index.h ...
[20] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/dfoliatR/in ...
...In the code above, we walked down the whole HTML tree body > div > table. The html_element() function will pickup HTML tags without providing the exact path, which is very convenient but can lead to unexpected results. The code below leads to the same results, but only because this page only has one HTML table. If it had multiple, it would only pick up the first one whether that was our intent or not. This point is very important to understand for more complicated web pages.
{html_node}
<table border="1">
[1] <tr>\n<th> Date </th> <th> Package </th> <th> Title </th> </tr>\n
[2] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/DrugSim2DR/ ...
[3] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/gmapsdistan ...
[4] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/actxps/inde ...
[5] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/AgroR/index ...
[6] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/aplot/index ...
[7] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/av/index.ht ...
[8] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/basemodels/ ...
[9] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bayesPop/in ...
[10] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/Bayesrel/in ...
[11] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/beanz/index ...
[12] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bookdown/in ...
[13] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bruceR/inde ...
[14] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/canvasXpres ...
[15] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CARBayes/in ...
[16] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/clinDR/inde ...
[17] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/cmm/index.h ...
[18] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/complexlm/i ...
[19] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CPC/index.h ...
[20] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/dfoliatR/in ...
...Fortunately, rvest has a handy html_table() function that’s specifically for HTML tables and automatically coerces them into a list of tibbles. I used bind_rows() to coerce the list to a tibble. As you can see below, we end up with a table of packages with a date, package name, and title.

The table from above has the package names, but it doesn’t include most of the package metadata. Going back to the site, you can see the package name has a link to another page that contains all that data.
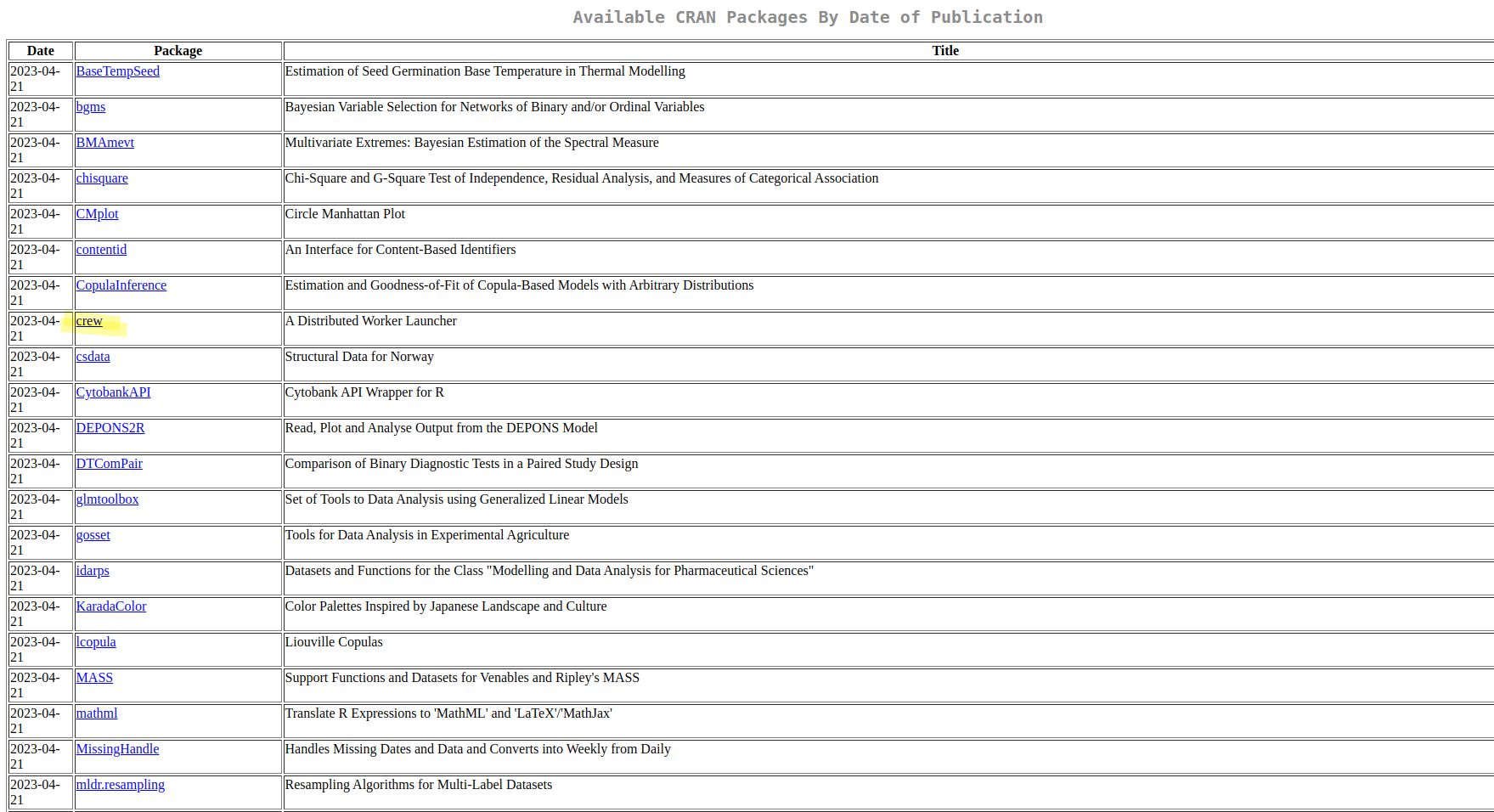
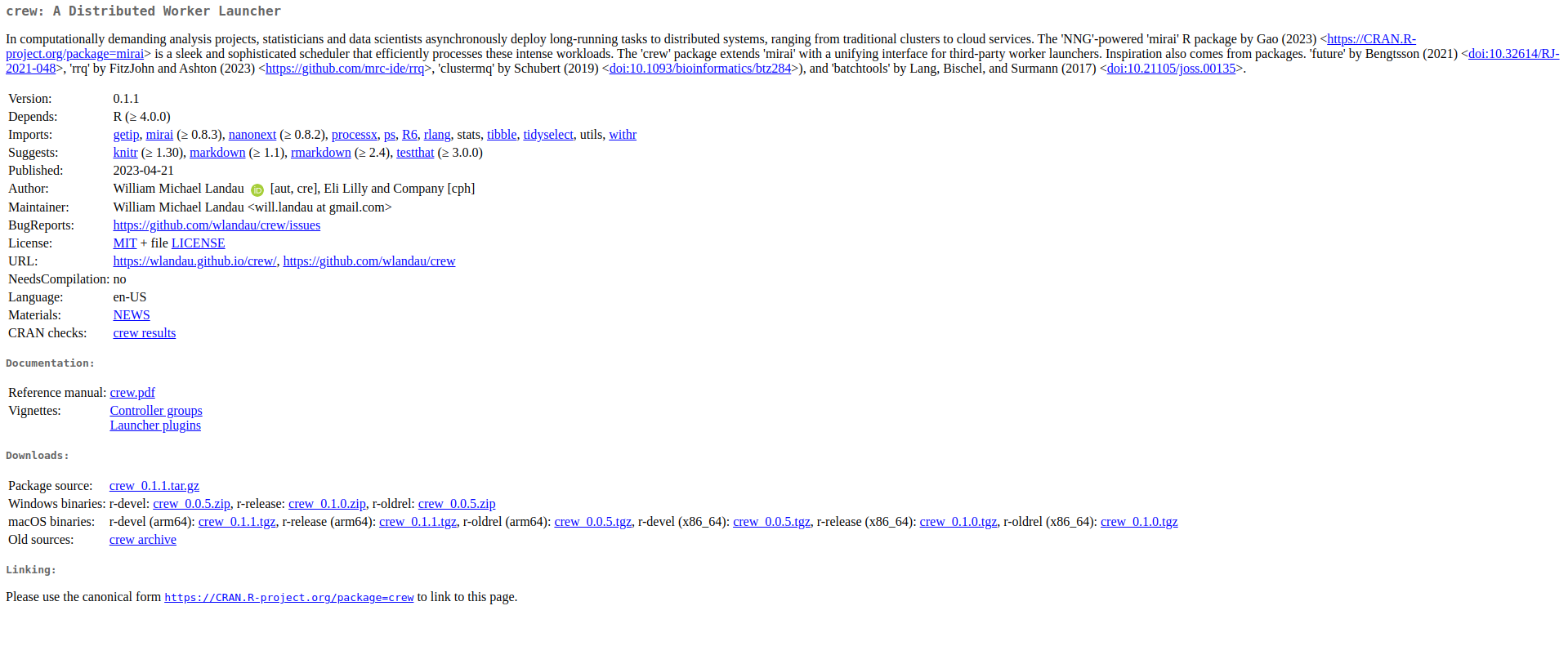
If we wanted to obtain the URL’s, we need to parse the <table>. Using html_children() again we can see that <table> contains <tr> tags, which is HTML table rows.
{xml_nodeset (19903)}
[1] <tr>\n<th> Date </th> <th> Package </th> <th> Title </th> </tr>\n
[2] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/DrugSim2DR/ ...
[3] <tr>\n<td> 2023-08-10 </td> <td> <a href="../../web/packages/gmapsdistan ...
[4] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/actxps/inde ...
[5] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/AgroR/index ...
[6] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/aplot/index ...
[7] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/av/index.ht ...
[8] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/basemodels/ ...
[9] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bayesPop/in ...
[10] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/Bayesrel/in ...
[11] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/beanz/index ...
[12] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bookdown/in ...
[13] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/bruceR/inde ...
[14] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/canvasXpres ...
[15] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CARBayes/in ...
[16] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/clinDR/inde ...
[17] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/cmm/index.h ...
[18] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/complexlm/i ...
[19] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/CPC/index.h ...
[20] <tr>\n<td> 2023-08-09 </td> <td> <a href="../../web/packages/dfoliatR/in ...
...Then we can go a level lower and see all the elements in the rows. Notice, we use the html_elements() (plural) function instead of html_element(). That’s because each row has multiple elements and html_element() will only parse the first element. We can a <td> tag, which is an HTML data cell, and an <a> tag, which is a hyperlink. The <a contains href="../../web/packages/.... An href is an HTML attribute for creating hyperlinks on a web page.
{xml_nodeset (59709)}
[1] <th> Date </th>
[2] <th> Package </th>
[3] <th> Title </th>
[4] <td> 2023-08-10 </td>
[5] <td> <a href="../../web/packages/DrugSim2DR/index.html"><span class="CRA ...
[6] <td> Predict Drug Functional Similarity to Drug Repurposing </td>
[7] <td> 2023-08-10 </td>
[8] <td> <a href="../../web/packages/gmapsdistance/index.html"><span class=" ...
[9] <td> Distance and Travel Time Between Two Points from Google Maps </td>
[10] <td> 2023-08-09 </td>
[11] <td> <a href="../../web/packages/actxps/index.html"><span class="CRAN">a ...
[12] <td> Create Actuarial Experience Studies: Prepare Data, Summarize\nResul ...
[13] <td> 2023-08-09 </td>
[14] <td> <a href="../../web/packages/AgroR/index.html"><span class="CRAN">Ag ...
[15] <td> Experimental Statistics and Graphics for Agricultural Sciences </td>
[16] <td> 2023-08-09 </td>
[17] <td> <a href="../../web/packages/aplot/index.html"><span class="CRAN">ap ...
[18] <td> Decorate a 'ggplot' with Associated Information </td>
[19] <td> 2023-08-09 </td>
[20] <td> <a href="../../web/packages/av/index.html"><span class="CRAN">av</s ...
...We can extract attributes using htm_attr() which will parse the text into a character vector.
In the code above, we walked down the whole HTML tree, but again we could’ve jumped down the tree like so. Just understand that this can lead to us picking up other hyperlinks that aren’t in our table (there are none of this page).
However, we do have to specify an HTML element before using html_attr() otherwise we’ll just get back NA.
One thing that’s worth mentioning is the URL’s we collected are relative paths, which is why they have /../ in the path.
[1] "../../web/packages/DrugSim2DR/index.html"
[2] "../../web/packages/gmapsdistance/index.html"
[3] "../../web/packages/actxps/index.html" This is a good point to take step way back to the beginning to introduce a few additional concepts, but if you made it this far you’ve learned enough to scrape a lot of websites with no additional tools. The html_ functions in rvest provide the core tools necessary to parse HTML which is what scraping is…
Up to this point, we’ve read HTML pages directly using read_html(). That would get pretty cumbersome if we want to read dozens of pages, let alone the 20K CRAN package pages.
When we use read_html() we copy the page to RAM as discussed earlier, but if we want to read hundreds of pages of a site we want to open an active web connection, or a session if you will :smile: Yup, you guessed it, that’s where rvest’s session() function comes into the picture.
We can do everything we did in the prior session using a session object.
Rows: 19,902
Columns: 4
$ Date <chr> "2023-08-10", "2023-08-10", "2023-08-09", "2023-08-09", "2023-…
$ Package <chr> "DrugSim2DR", "gmapsdistance", "actxps", "AgroR", "aplot", "av…
$ Title <chr> "Predict Drug Functional Similarity to Drug Repurposing", "Dis…
$ href <chr> "../../web/packages/DrugSim2DR/index.html", "../../web/package…And we can use the session_ verbs such as session_jump_to() to go to relative pages on the site.
We could use session_jump_to() because we scraped all the package page URL’s earlier, but we could also use session_follow_link() to effectively click on the hyperlinks. The code below accomplishes the same thing as the prior block. However, the session_follow_link() function can be challenging to use with i because it only takes a session object and uses an internal function, find_href(), which uses html_elements("a") to find all hyperlinks on the page and follows the ith hyperlink in that vector. It wraps session_jump_to(), which inherently provides you with significantly more control.
[1] "rvest: Easily Harvest (Scrape) Web Pages"Now that we have the detail page for rvest, we can structure parse and structure the package metadata using the same set of tools we’ve used along the way and a few stringr and janitor functions to clean text.
library(htmltools)
package <- rvest_details |>
html_element("body") |>
html_element("div") |>
html_element("h2") |>
html_text() |>
str_split_i(pattern = ":", i = 1)
description <- rvest_details |>
html_element("body") |>
html_element("div") |>
html_element("h2") |>
html_text() |>
str_split_i(pattern = ":", i = 2) |>
str_squish()
package_tables <- rvest_details |>
html_element("body") |>
html_element("div") |>
html_elements("table")
package_details <- map(package_tables, function(x){
pack_table <- x |>
html_table()
}) |>
bind_rows() |>
rename("key" = "X1", "value" = "X2") |>
mutate(value = str_trunc(value, width = 300))
rvest_table <- reactable(package_details, filterable = T, pagination = FALSE)
div(class = "reactable-tbl-view",
div(class = "div-subtitle",
div(class = "div-title", package),
description
),
rvest_table
)There’s very little additional work to do in order to scrape all package packages and bind them to our initial data frame. I’m not going to run the code for all packages because there’s a faster way to get this data, but I run it here for a subset to demonstrate.
library(janitor)
subset_cran_packages_df <- cran_packages_df[1:15,]
package_details_df <- map(
subset_cran_packages_df$href,
function(url){
package_page <- sesh_cran_packages |>
session_jump_to(url = url) |>
read_html()
package_description <- package_page |>
html_element("body") |>
html_element("div") |>
html_element("h2") |>
html_text() |>
str_split_i(pattern = ":", i = 2) |>
str_squish()
package_page_tables <- package_page |>
html_element("body") |>
html_element("div") |>
html_elements("table")
package_details <- map(package_page_tables, function(ppt){
ppt |>
html_table() |>
pivot_wider(names_from = "X1", values_from = "X2")
}) |>
bind_cols() |>
mutate(across(.cols = everything(), .fns = ~stringr::str_trunc(.x, width = 225))) |>
mutate(description = package_description, .before = 1)
return(package_details)
}) |>
bind_rows() |>
clean_names("snake")
packages_reactable <- bind_cols(subset_cran_packages_df, package_details_df) |>
reactable(filterable = TRUE, pagination = T, paginationType = "numbers", defaultPageSize = 5)
div(class = "reactable-tbl-view",
packages_reactable
)Above, we were able to scrape the site so we could gather the data for all pacakges pretty easily. That said, thanks to a helpful post from Jeroen Ooms, we can download all the package data from those pages (and then some) with the below code. Much simpler than all that scraping, but the data frame is 67 columns so I’m going to hold of on printing the entire thing. On that note, it’s always worth a little research to see if the site offers their data or an API before doing any scraping.
Now that we’ve learned how to scrape, it’s time to discuss etiquette. The web has some rules regarding how you can programmatically use web sites. Sites publish their rules in their robots.txt file. Most sites on the web have a robots.txt file and it lives directly in the site’s root directory. As an example, here’s Netflix’s. These files tell us what pages the site administrator does not want us accessing and using programmatically. CRAN’s robot.txt asks that we not scrape the DESCRIPTION page of each package, but they don’t mention the index.html pages we scraped in our example so we didn’t violate their rules.

The polite library implements a framework to help users follow site rules and use best practices when scraping with a set of verbs. Beyond making it painless to follow site rules, polite also wraps in a number of features that may save you a lot of time in the long-run including caching. The first verb to learn in polite is bow(). We can us bow in place of rvest’s session() function. The bow() function provides some nice features, but it’s main purpose is to create a session and introduce us to the host before we make a request.
After bowing, we can use scrape() in place of read_html(). The scrape() function reads in the HTML document in the same way that read_html() does, but also directly provides some useful parameters including query. The query parameter provides an easy way to add URL parameters for filtering certain pages.
We can also use nod() to ask the host if we can modify the session path before scraping the URL paths and it will tell us if we’re violating the site rules.
<polite session> https://cran.r-project.org/../../web/packages/DrugSim2DR/index.html
User-agent: www.mark-druffel.com (mark.druffel@gmail.com)
robots.txt: 19919 rules are defined for 1 bots
Crawl delay: 1 sec
The path is scrapable for this user-agent[1] "DrugSim2DR"
If we are violating the rules, polite tell us when we nod and will stop us from going further.
<polite session> https://cran.r-project.org/web/packages/rvest/DESCRIPTION
User-agent: www.mark-druffel.com (mark.druffel@gmail.com)
robots.txt: 19919 rules are defined for 1 bots
Crawl delay: 1 sec
The path is not scrapable for this user-agentWarning: No scraping allowed here!NULLFinally, polite provides a the rip() function to download files politely.
We’ve learned how to scrape, to page through a website, and to do all this with proper decorum, but we learned all of these skills on a completely static site. We didn’t have to interact with any buttons, sign in pages, on page filters, or hit any servers once we were on the page to see the data we wanted to scrape. These on-screen actions can be a bit more complicated and require the use of additional software, which I’ll demonstrate.
Awhile back, I was job searching and built a scraper that helped me search LinkedIn for jobs that met my criteria. LinkedIn’s job search filters just don’t do enough. Plus, LinkedIn has so many duplicated posts and all the sponsored posts are always at the top. Job searching basically becomes a full-time job because none of the tools are built for the users’ benefit, they’re built for the business model. So yeah, I didn’t want to endlessly scroll through the dystopian hellscape that is the LinkedIn experience to try to find jobs… so that’s why I built a scraper! At that time, screen scraping was frowned upon, but Linkedin had unsuccessfully sued HiQ Labs for scraping and lost so it seemed like the worst case scenario was LinkedIn would close my account. That would suck, but it wouldn’t be that big of a deal. As I’m writing this post, I’m realizing they were recently able to get that ruling reversed and win in court. Many of the articles I’m seeing from the business journalists mention “LinkedIn winning in a suit to protect user data and privacy…” Thank goodness Microsoft is protecting our data from nefarious start-ups so that only they can benefit from it… 🤢

Anyhow, all this to say, I wrote this scraper before the suit and I’m not suggesting it be used by anyone. I’m only publishing this work to demonstrate how to use these tools, I’d encourage you use the polite framework in order to avoid any legal issues.
For fun, I tried to rerun my code using polite and build on our prior examples and bow() responded with….. 🤣
Warning: Psst!...It's not a good idea to scrape here!
You may have noticed rvest’s _form functions. Pages can have forms, the most common of which is a sign in. We cam use these to fill out forms and hit submit without using a full-fledged web driver like RSelenium. LinkedIn has a few pages that can be used to sign-in, but I worked from this one specifically because of it’s simplicity. You can inspect it with your web developer tools to easily see the structure - for larger sites like this I find it’s much easier to start there and then go to RStudio to use the tools we have up to this point.
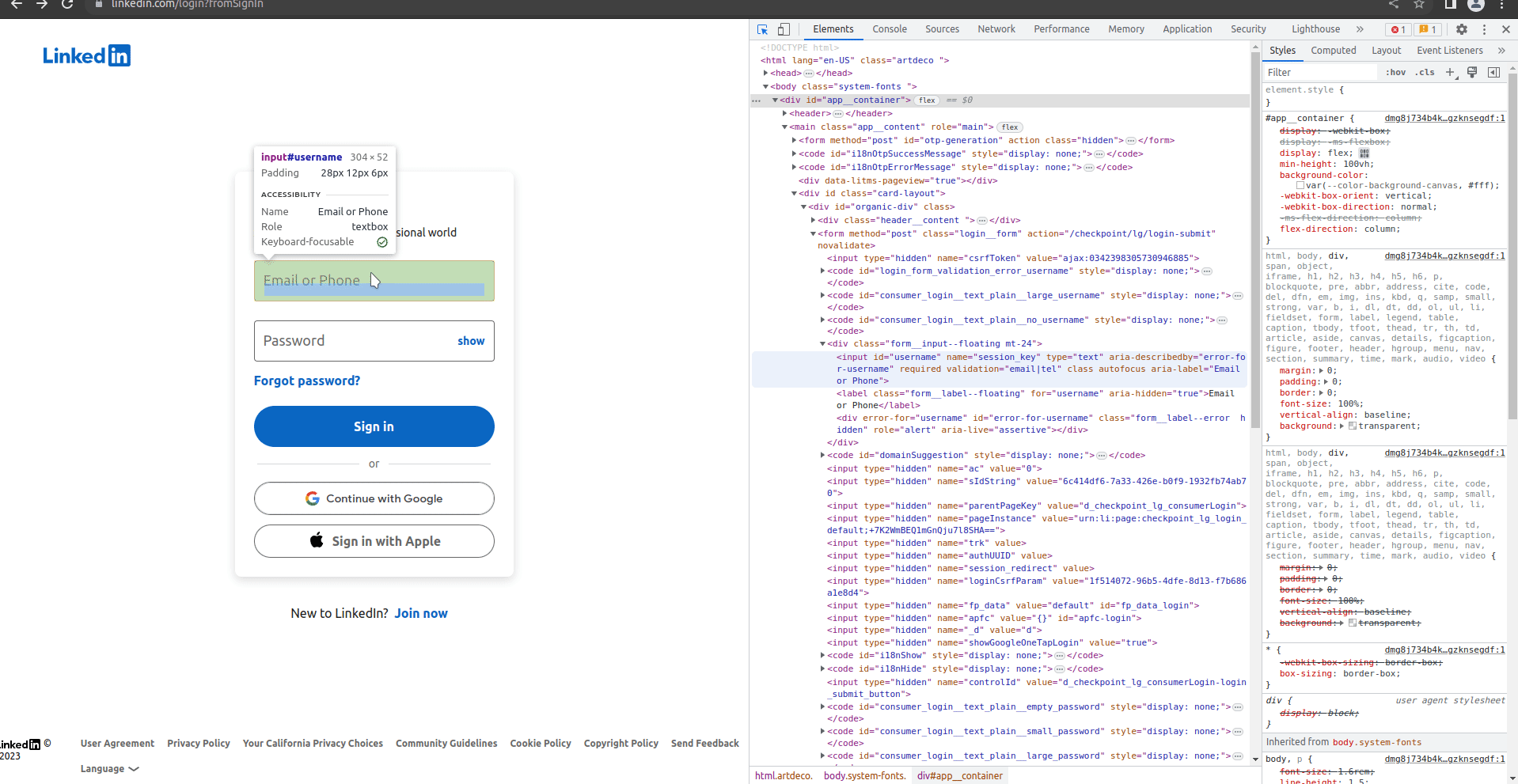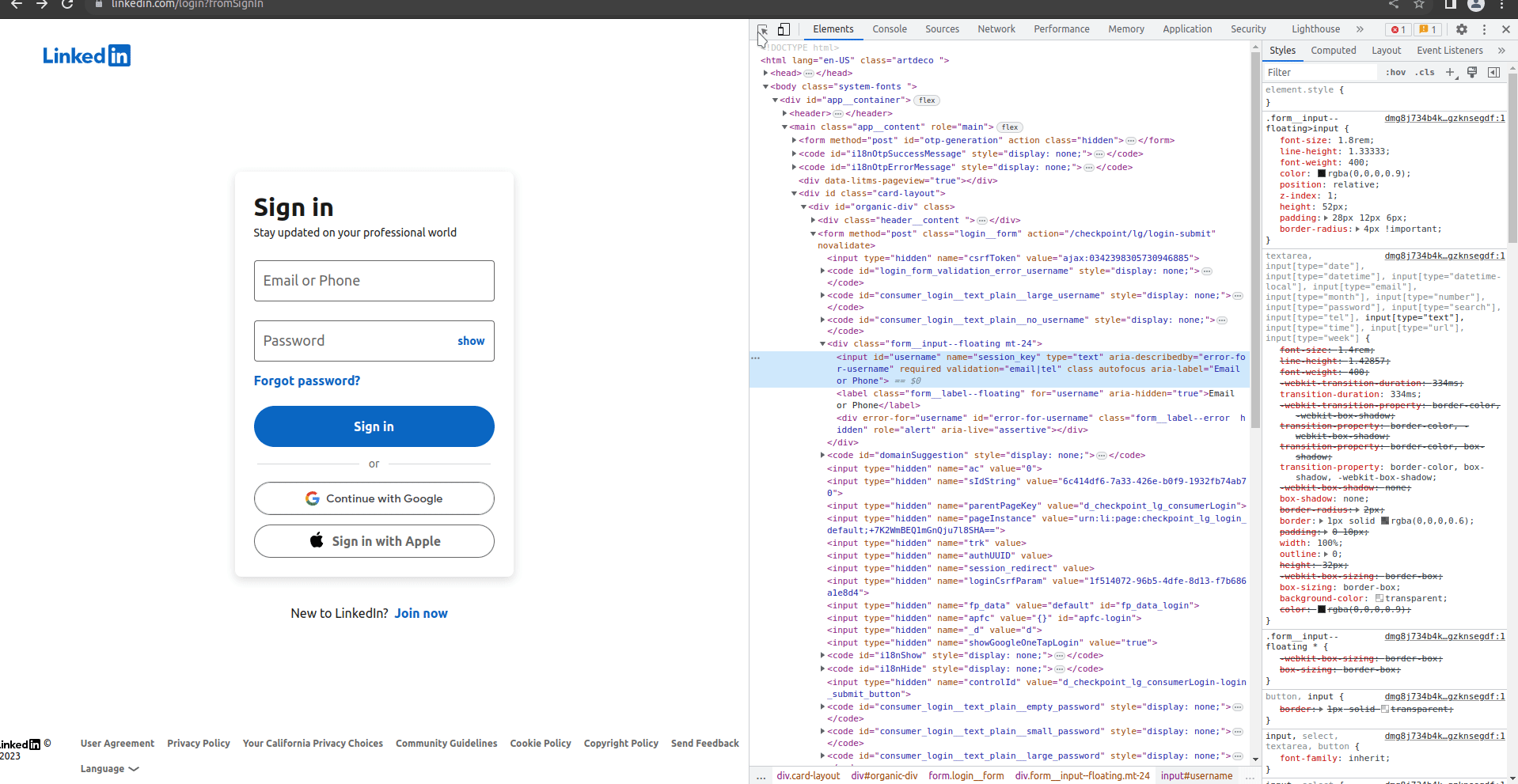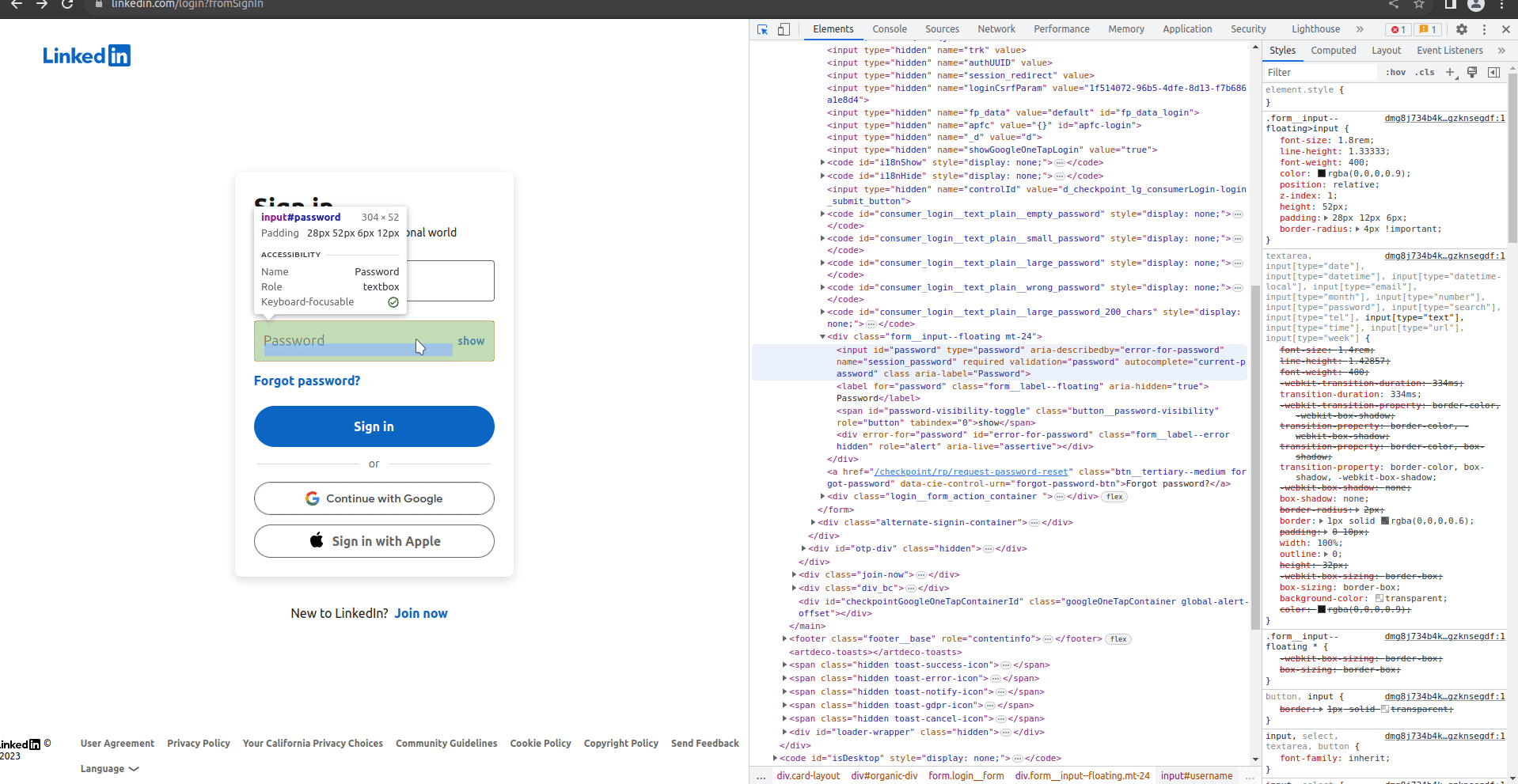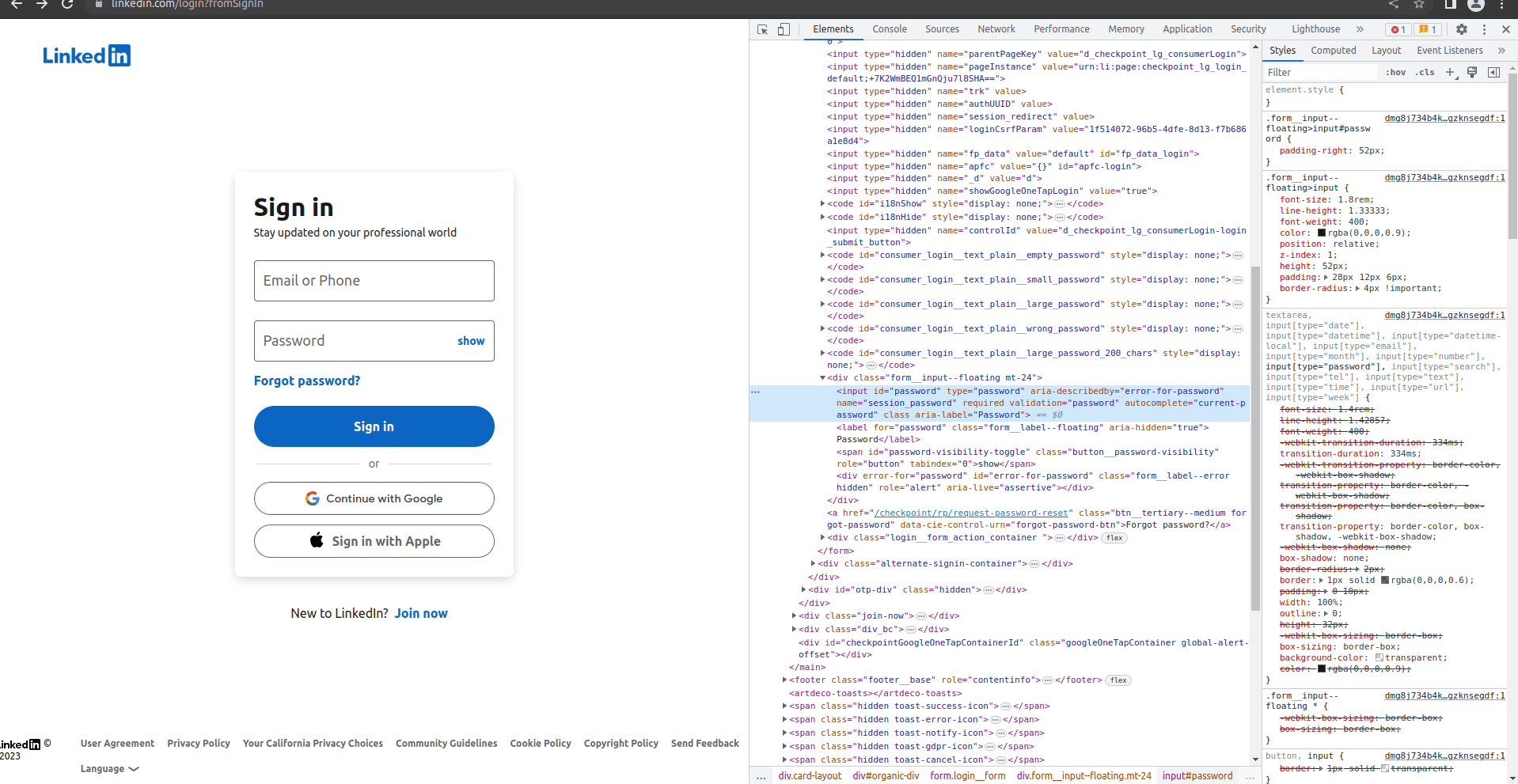
When I tried to use the rvest tools, I had a tough time getting them to work for this page. I’m not entirely sure, but it looks like LinkedIn’s submit button doesn’t have a name in the form when I scrape it. That said, in my browser tools I can see the name show up as Sign In. I tried using Sign In in the submit parameter in html_form_set(), but it didn’t work either. Not sure what I’m doing wrong, but that’s ok because we’ll need RSelenium if we go any further so we can just jump into it.
library(glue)
li <- session("https://www.linkedin.com/login?fromSignIn")
login_forms <- li |>
read_html() |>
html_form()
li <- login_forms[[2]] |>
html_form_set(session_key = Sys.getenv("LINKEDIN_UID"), session_password = Sys.getenv("LINKEDIN_PWD")) |>
html_form_submit()
glue("I requested `{li$request$url}` and was redirected to `{li$url}") As I mentioned in the intro, RSelenium allows you to drive web browsers from R. RSelenium is an R package that provides bindings to Selenium, which is what actually drives the web browser. To use RSelenium, we have a couple options. Option one, run a server either on your machine or in docker and connect to it. Option two, run Selenium locally. For posterity, I’ll cover how to setup and connect to a docker instance running Selenium, but for the demonstration I’ll just us Selenium locally.
If you’re not familiar with docker, I recommend Colin Faye’s An Introduction to docker for R Users. To get docker setup for Selenium, I heavily reference RSelenium’s docker documentation and the SeleniumHQ docker documentation. If you don’t have docker on your machine, you can install it here. You can also install docker desktop here if you like. The docker installation is required, but docker desktop is just helpful. Kind of like R is required and RStudio is just helpful.
Once you’ve installed docker, you need to pull an image with Selenium (or create one). To start, I followed the RSelenium docs. RSelenium refers to this image, which you can pull the image (i.e. get a copy of it to run on your machine) in terminal with the below code.
That standalone image works just fine for scraping, but if you want to be able to observe your code working, you’ll need to download the debug version.
Regardless, firefox:2.53.0 is pretty out of date. It uses Firefox version 47.0.1, which was released in 2016. The newest version on Selenium’s docker docs at the time of writing this is firefox:4.9.0-20230421, which uses Firefox version 112.0.1 (released in 2023). This later version also has debugging capbailities built in so there is no need to pull a -debug version. We can pull whatever is the latest version (right now 4.9.0-20230421) by removing the version or explicitly using latest. However, I couldn’t get version 4.9.0-20230421 and see in this issue that other users bumped into the same roadblock.
In the Github issue comments, the fvalenduc said he tested the versions and the newest working version with RSelenium was 3.141.59.
You can start the docker container with the code below. The first port (i.e. -p 4445) is the Selenium server, the second is used to connect to a web server to observe the Selenium.
We can also start our Selenium server from R using the system command. This is helpful if you want to create a script or package your code. If you’re using Linux and docker is owned by root, you can either add your user to the docker group or pipe your sudo password into your command (shown in second system() call below).
We can connect to the docker container using the remoteDriver() class. As I mentioned before, the latest version would not work for me… It would hang if I ran latest$open(). Once you open a connection, you can drive the browser from there. I’ll cover driving the web driver section.
library(RSelenium)
# Connect to 3.141.59
rdriver <- remoteDriver(
remoteServerAddr = "0.0.0.0",
port = 4445L,
browserName = "firefox",
version = "47.0.1",
platform = "LINUX",
javascript = T
)
# Connect to latest
latest <- remoteDriver(
remoteServerAddr = "172.17.0.2",
port = 4444L,
browserName = "firefox",
version = "112.0",
platform = "LINUX",
javascript = T
)
# Open the connection and navigate to a website
rdriver$open()
rdriver$navigate("www.google.com")If you don’t know the remoteServerAddr, there are several ways to get that info. First, you can run docker ps. The output can look a little confusing, but you should be able to figure out what the server’s IP address is.SDM
You can also run docker ps from R. I couldn’t find a library that simplified interacting with Docker from R, but I’m sure one exists. I’ve written a few wrappers around ps, but never tried to do anything
library(tidyverse)
images <- system(glue::glue("echo {Sys.getenv('SUDO_PWD')} | sudo -S docker ps"), ignore.stdout = F, intern = T)
ips <- as_tibble(str_locate(images, pattern = "[0-9]??\\.[0-9]??\\.[0-9]??\\.[0-9]??:"))
ips <- pmap_dfr(list(i = images[2:5], s = ips[2:5, ]$start, e = ips[2:5, ]$end), function(i, s, e){
ip <- str_sub(i, start = s, end = e-1)
tibble(ip = ip)
})
names <- as_tibble(str_locate(images, pattern = "selenium.*firefox:[a-z0-9]+(?:[._-][a-z0-9]+)*|selenium.*firefox-debug:[a-z0-9]+(?:[._-][a-z0-9]+)*"))
names <- pmap_dfr(list(i = images[2:5], s = names[2:5, ]$start, e = names[2:5, ]$end), function(i, s, e){
name <- str_sub(i, start = s, end = e)
tibble(name = name)
})
docker <- bind_cols(names, ips) |>
bind_cols(images[2:5]) |>
rename("ps" = 3L)
docker |>
filter(str_detect(name, pattern = "latest|firefox:4."))# A tibble: 0 × 3
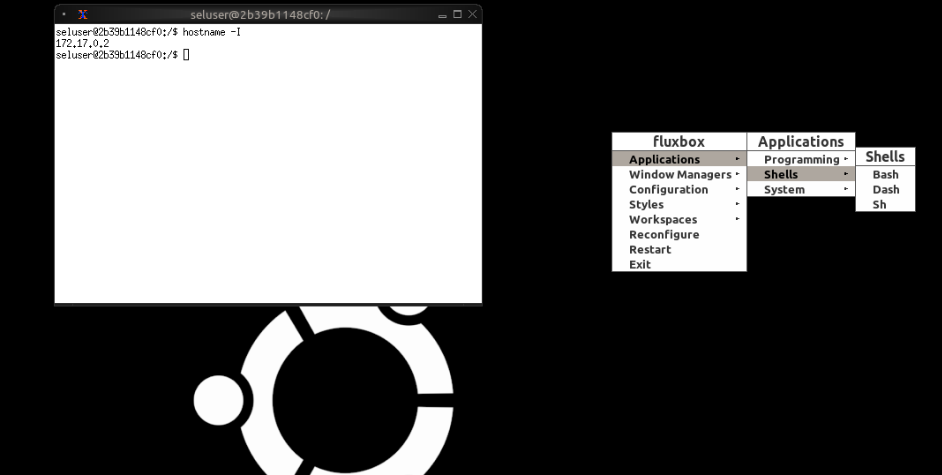
# ℹ 3 variables: name <chr>, ip <chr>, ps <chr>Another option is to look on docker hub to see the environment variables set in the docker image. The NODE_HOST variable is the remote server address you should use. Alternatively, you can log into the web server, right click on the desktop, launch bash, and run hostname -I.
If you’re using a newer version of Selenium, once you have the IP, you can connect to Selenium Grid via endpoints using httr to get other info. This won’t work for the older versions that don’t use Selenium Grid.
You can log into the web server to get info from the machine, install updates, etc. if you want to, but the most useful aspect of doing so imho is the ability to watch your scraping program work in the browser while it’s running. You can make sure it’s doing what you intended so it doesn’t fly off the rails. To log into the web server, you’ll need a remote desktop app. The latest Selenium version comes with noVNC, but you’ll need to install your own when using the older -debug versions. I used Vinagre. You will be prompted for a password, I couldn’t figure out where that’s set in docker but found in the documentation that it is secret.
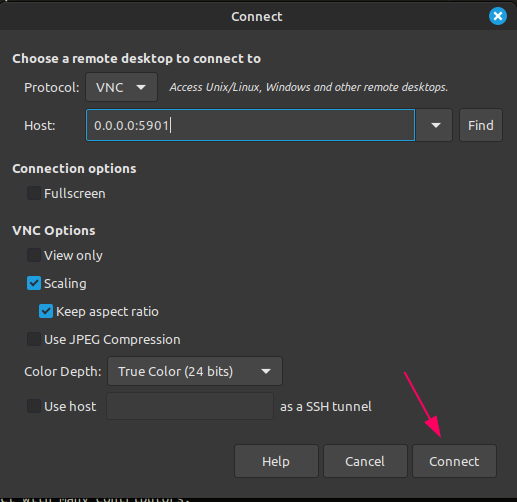
When using the latest versuib you can simply access the web sever through your browser by going to http://localhost:7900/?autoconnect=1&resize=scale&password=secret.
RSelenium allows us to install binaries and run Selenium locally in our browser of chance through the wdman package with the rsDriver function which creates a remoteDriver locally (i.e. you can use it the same way you would use remoteDriver() once the connection is established). I had some issues with firefox on Ubuntu 22, but I was able to get Chrome working by updating Chrome and turning off check.
First, we need to sign into LinkedIn so we can view all the pages. The findElement() method works similarly to html_element() from rvest, but we can access other methods to interact with the HTML element. Below, we used sendKeysToElement() in order to enter our credentials, the clickElement() to submit, and the getCurrentUrl() method to confirm the sign-in worked properly.
driver$client$navigate("https://www.linkedin.com/login?fromSignIn")
Sys.sleep(3)
driver$client$screenshot(file = "images/sign_in_page.png")
driver$client$findElement("name", "session_key")$sendKeysToElement(list(Sys.getenv("LINKEDIN_UID")))
driver$client$findElement("name", "session_password")$sendKeysToElement(list(Sys.getenv("LINKEDIN_PWD")))
driver$client$findElement("tag name", "BUTTON")$clickElement()
driver$client$maxWindowSize()
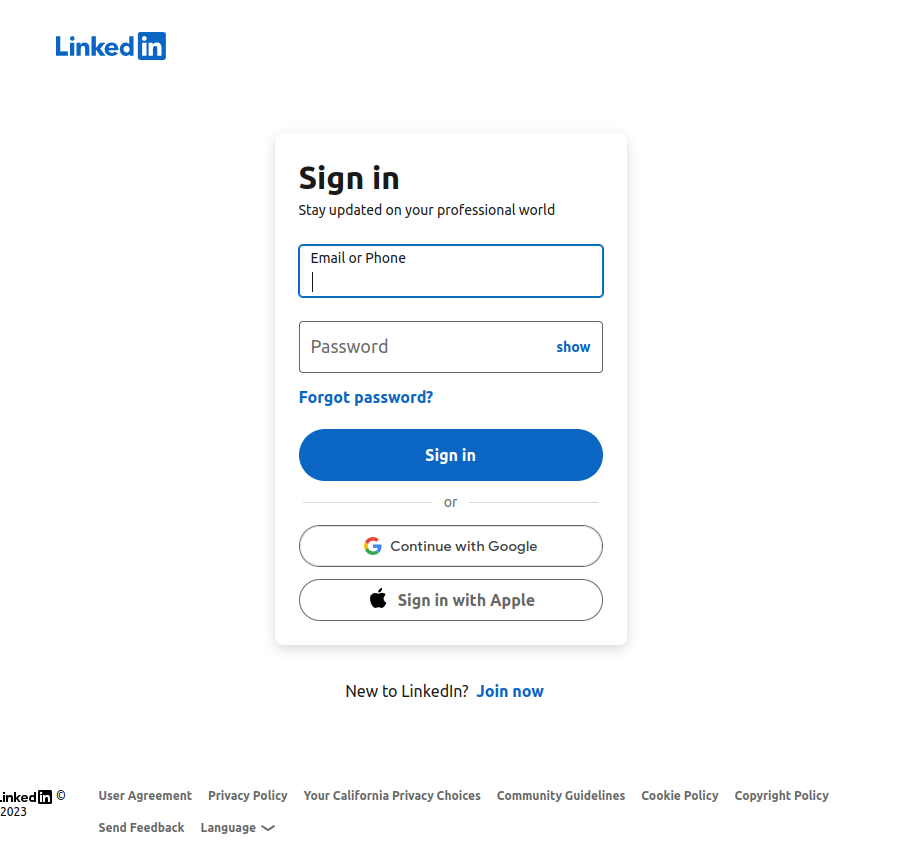
Once we’ve signed in, we can interact with the site under our username. We could fill in the search forms, but I want to do a few different job searches and the parameters all go in the URL as query parameters so I’m just going to build a URL using glue and URLencode.
You may notice the use of minimize_messaging() in the job search code. I created a function to minimize personal messaging just so it wouldn’t be open for screen shots. This wouldn’t have been nessary if I wasn’t publishing automatically generated screenshots for this post…
minimize_messaging <- function(driver){
html <- xml2::read_html(driver$client$getPageSource()[[1]], options = "HUGE")
df_messaging <- tibble(
id = html |> html_element("aside") |> html_elements("button") |> html_attr("id"),
icon_type = html |> html_element("aside") |> html_elements("button") |> html_element("li-icon") |> html_attr("type")
) |>
filter(icon_type == "chevron-down")
if(nrow(df_messaging) == 1){
id <- df_messaging$id
driver$client$findElement("id", id)$clickElement()
}
}remote_and_hybrid <- "f_WT=2,3"
keywords <- "keywords=data analyst | data scientist"
location <- "Portland, Oregon Metropolitan Area"
geo <- "geoId=90000079"
jobs_url <- URLencode(glue::glue("https://www.linkedin.com/jobs/search/?{remote_and_hybrid}&{geo}&{keywords}&{location}&refresh=T"))
driver$client$navigate(jobs_url)
Sys.sleep(3)
minimize_messaging(driver)
Sys.sleep(1)
driver$client$screenshot(file = "images/job_search.png")
jobs_html <- xml2::read_html(driver$client$getPageSource()[[1]], options = "HUGE")
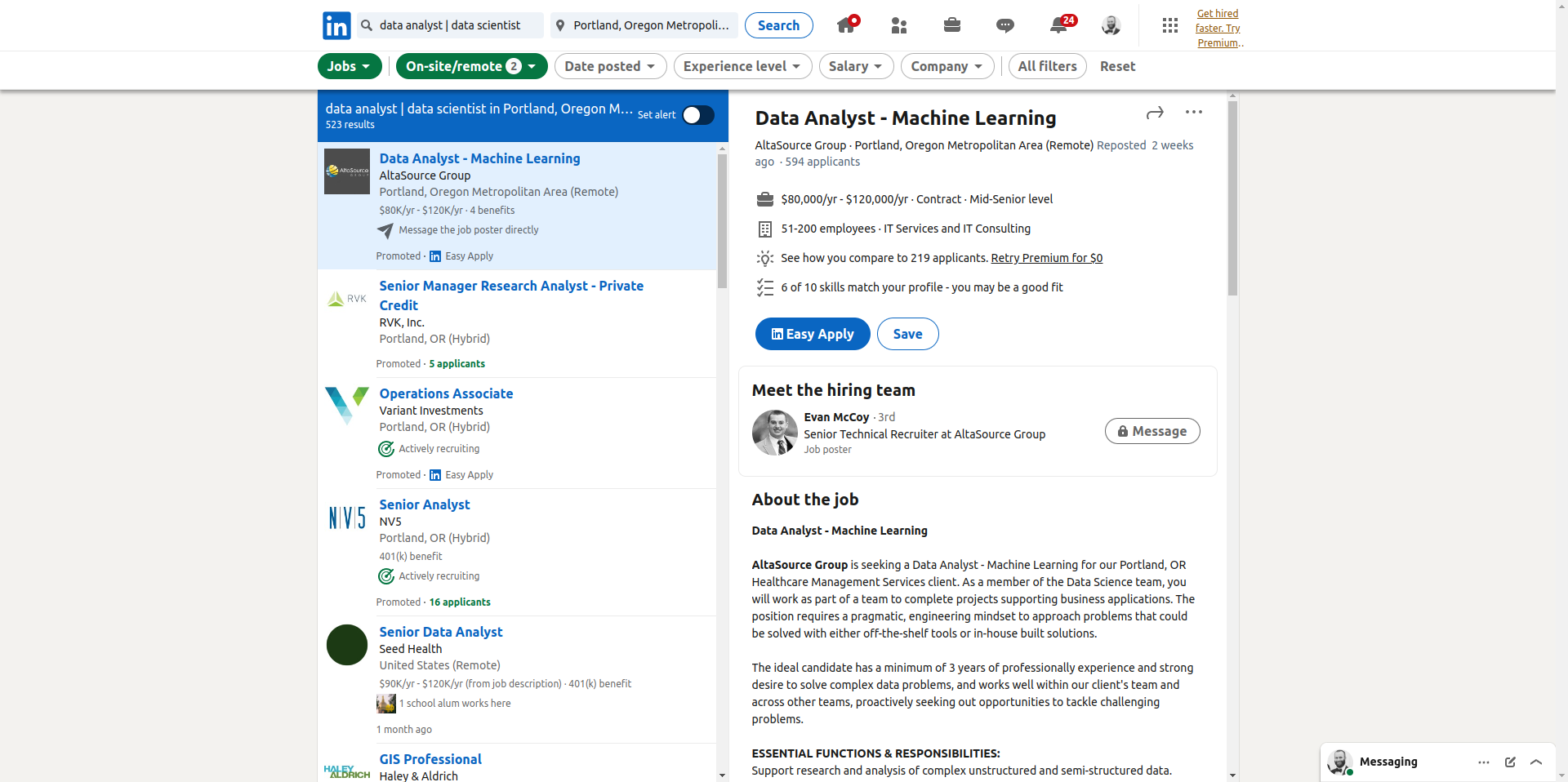
The search returns a bunch of jobs based on our search parameters in a number of pages. The list of jobs just has the role title, company name, and a few other basic job facts. The details of each job are in the detailed pages that we have to click into. We can extract the href attribute for each job listing to get a direct URL or the button id attribute so we can click the button through Selenium to open the job details pane. We can extract both of these things using the URL page links using html_attr. Remember, an <a> tag is used for hyperlinks, the href stores the URL and the id uniquely identifies the tag. Since each hyperlink will have one href and one id, I just extracted the data into a tibble to make it easier to filter to only the buttons we want. That said, if you look at the list of job links you may notice there are less jobs than are actually in the web page… the reason for that is you have to scroll down the page to load all the jobs.
df_jobs <- tibble(
href = jobs_html |> html_elements("body") |> html_elements("a") |> html_attr("href"),
id = jobs_html |> html_elements("body") |> html_elements("a") |> html_attr("id")
) |>
filter(str_detect(href, pattern = "/jobs/view/")) |>
mutate(href = paste0("https://www.linkedin.com", href))
glue::glue("df_jobs has {nrow(df_jobs)} hrefs")df_jobs has 9 hrefsTo scroll down, we need to find an anchor point to tell Selenium to scroll to. I chose to use the paging buttons at the bottom of the list because I’ll need those later for paging through the list.
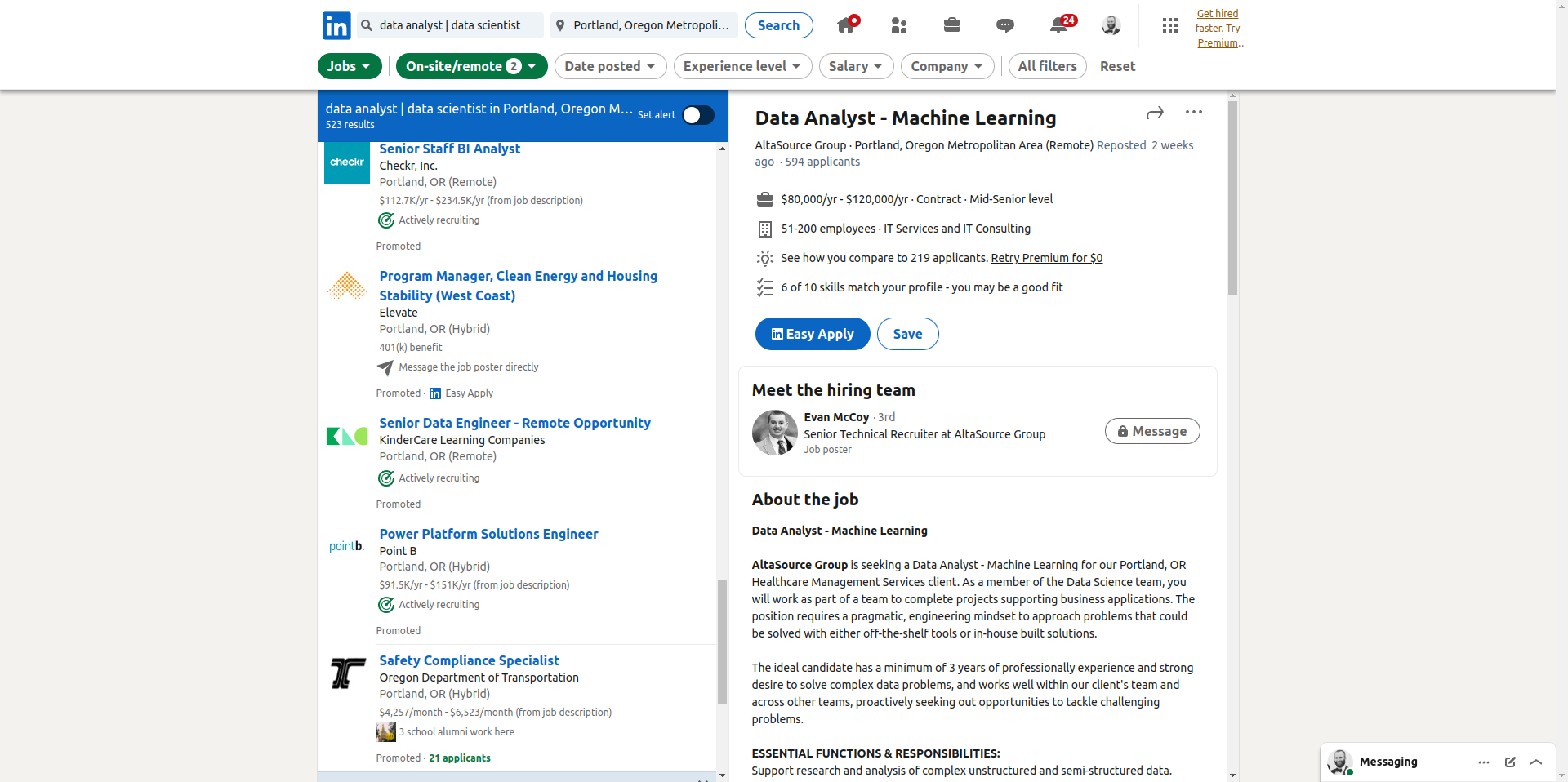
After you scroll down and retry scraping the jobs you’ll still be missing jobs from the list 😱 The site cleverly only loads as you scroll down the page. I tried a few more elegant ways to load the whole list including the down arrow (which is disabled in the jobs list view) and using a custom JavaScript script to send a mouse wheel event. Unfortunately, I couldn’t get those approaches to work and I was stuck with brute force…
jobs_html <- xml2::read_html(driver$client$getPageSource()[[1]], options = "HUGE")
df_jobs <- tibble(
href = jobs_html |> html_elements("body") |> html_elements("a") |> html_attr("href"),
id = jobs_html |> html_elements("body") |> html_elements("a") |> html_attr("id")
) |>
filter(str_detect(href, pattern = "/jobs/view/")) |>
mutate(href = paste0("https://www.linkedin.com", href))
glue::glue("df_jobs has {nrow(df_jobs)} hrefs")df_jobs has 14 hrefsMy brute force approach was basically to repeatedly use the getElementLocationInView() method on a random walk over the job HTML id’s. This approach causes Selenium to scroll the browser to get the job into the view, and by randomly ordering the jobs the scroll goes in both directions getting jobs to load. I wrote this process in a recursive function then scrapes the jobs until the random walk doesn’t get any additional jobs to load.
scrape_html <- function(driver){
html <- xml2::read_html(driver$client$getPageSource()[[1]], options = "HUGE")
return(html)
}
scrape_pages_df <- function(html){
df_pages <- tibble(
pagination_btn = html |> html_element("body") |> html_elements("li") |> html_attr("data-test-pagination-page-btn"),
id = html |> html_elements("body") |> html_elements("li") |> html_attr("id")) |>
mutate(pagination_btn = as.numeric(pagination_btn)) |>
mutate(pagination_btn_ellipsis = lag(pagination_btn) +1) |>
mutate(pagination_btn = coalesce(pagination_btn, pagination_btn_ellipsis), .keep = "unused") |>
filter(str_detect(id, "ember") & !is.na(pagination_btn))
return(df_pages)
}
randwalk_jobs <- function(driver, ids){
ids <- ids |>
sort() |>
sample()
purrr::walk(ids, function(id){
job_element <- driver$client$findElement("id", id)
job_element$getElementLocationInView()
naptime::naptime(.25)
})
}
scrape_jobs_df <- function(driver, n_jobs = 0){
if(n_jobs == 0){
html <- scrape_html(driver)
df_pages <- scrape_pages_df(html)
first_page_button_webElem <- driver$client$findElement("id", df_pages$id[1])
first_page_button_webElem$getElementLocationInView()
naptime::naptime(1)
}
html <- scrape_html(driver)
df_jobs <- tibble(
url = html |> html_elements("body") |> html_elements("a") |> html_attr("href"),
class = html |> html_elements("body") |> html_elements("a") |> html_attr("class"),
id = html |> html_elements("body") |> html_elements("a") |> html_attr("id"),
text = html |> html_elements("body") |> html_elements("a") |> html_text()
) |>
filter(str_detect(url, pattern = "/jobs/view/")) |>
filter(str_detect(class, patter = "job-card-list__title"))
if(n_jobs < nrow(df_jobs)){
randwalk_jobs(driver, df_jobs$id)
df_jobs <- scrape_jobs_df(driver, n_jobs = nrow(df_jobs))
} else{
return(df_jobs)
}
}
df_jobs <- scrape_jobs_df(driver)
glimpse(df_jobs)Rows: 25
Columns: 4
$ url <chr> "/jobs/view/3643896946/?eBP=CwEAAAGJ3hqxnFFynjFRp74ikNndcmugP453…
$ class <chr> "disabled ember-view job-card-container__link job-card-list__tit…
$ id <chr> "ember202", "ember214", "ember225", "ember236", "ember248", "emb…
$ text <chr> "\n Data Analyst - Machine Learning\n …Now that we have all the jobs loaded with href’s and id’s, we can open the job details to scrape out the data we want. We can either directly navigate to the job URL’s or open the job details pane. The former option is much easier, but it will cause another page load (slower) and it’s a user behavior that would not resemble a user on the site (i.e. it would look like a scraper). We’ve already covered all the methods required to do use either method (direct navigation or button clicking) in Job Search and Sign-in, respectively. I used the latter method to open the jobs using the id’s and the clickElement method.
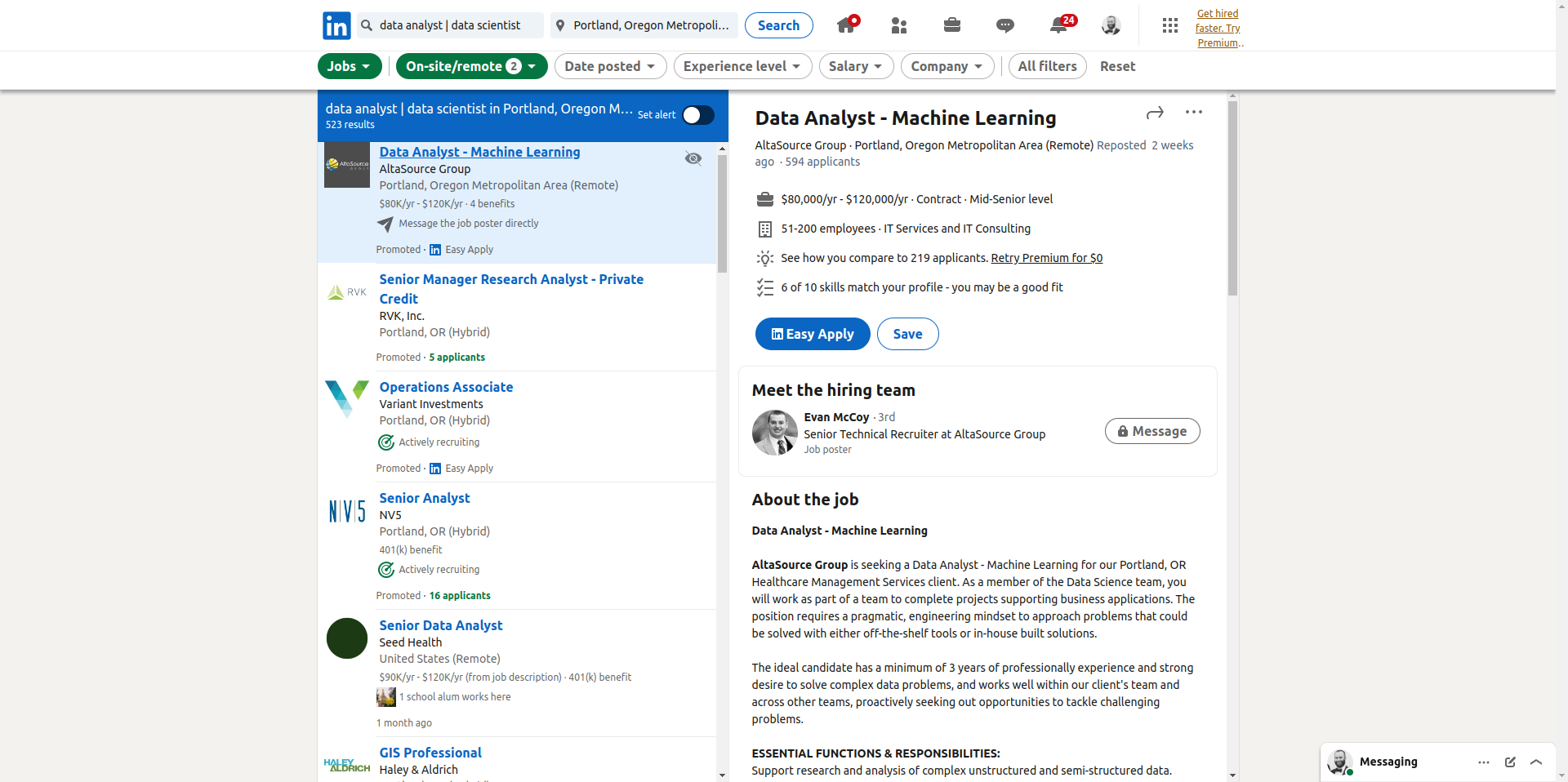
The job details pane was a total pain 😅 It was broken into a sections and I scraped a few of them - a top card which has some details about the company and role, the job description (text), salary data, and skills data. The skills data is inside a modal view. I’m not going to walk through all this code line by line because we’ve already walked through most these functions and methods, but I put everything in functions with long names to try to make it as easy to follow as possible. The main function, scrape_job_details() can pull all the data from the aforementioned sections (top card, description, salary, skills) and puts it all in a data frame. The one new idea that shows up here that didn’t in prior sections in this post is error handling. Error handling deserves its own separate post so I’m not going to dive into it here, but if you write a scraper that does interactive things (clicking, log-ins, paging) you will need error handling. Sometimes your code will be slightly faster than the browser and it causes random glitches. Also, sometimes if you scrape enough data some parts of the site might not be structured the same way due to edge cases, errors, etc. There are several libraries and base functions available for error handling, but I used purrr because I thought possibly() and insistently would be the easiest / best for what I was doing. If it wasn’t apparent up to now, you can see screen scraping can be a lot of work. Further, if the page changes some of the classes and structures may change and break our code 😅
# pane is what we're scraping, but I wrote my functions to work for page if you click into the job's url (whole page job listing)
scrape_job_details_df <- function(driver, id = NULL, view = c("pane", "page")){
html <- scrape_html(driver)
html_job_details <- extract_job_details_html(html, view)
html_top_card <- extract_top_card_html(html_job_details, view)
df_job_details <- scrape_top_card_df(html_top_card)
html_job_desc_card <- extract_job_desc_card_html(html_job_details)
df_job_desc <- scrape_job_desc_df(html_job_desc_card)
df_job_details <- dplyr::bind_cols(df_job_details, df_job_desc)
html_salary_card <- extract_salary_card_html(html_job_details)
df_job_details <- dplyr::bind_cols(
df_job_details,
scrape_salary_df(html_salary_card))
open_skills_button_id <- get_skills_open_button_id(html_job_details)
open_skills_click_result <- click_button(driver, "id", open_skills_button_id, nap_length = "long")
if(open_skills_click_result == "Success"){
html <- scrape_html(driver)
html_skills_modal <- extract_skills_modal_html(html)
close_skills_button_id <- get_skills_close_button_id(html_skills_modal)
close_skills_click_result <- click_button(driver, "id", close_skills_button_id, nap_length = "short")
if(close_skills_click_result != "Success"){driver$client$goBack()}
skills <- scrape_skills_chr(html_skills_modal)
df_job_details$skills <- list(skills)
} else {
skills <- NA_character_
df_job_details$skills <- list(skills)
}
df_job_details$id <- id
return(df_job_details)
}
extract_job_details_html <- function(html, view = c("pane", "page")){
view <- match.arg(view, choices = c("pane", "page"), several.ok = F)
if(view == "pane"){
class_pattern <- "scaffold-layout__detail"
} else if(view == "page"){
class_pattern <- "job-view-layout jobs-details"
} else{
class_pattern <- "jobs-details"
}
job_details_html_index <- tibble::tibble(class = html |> rvest::html_elements("body") |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(class, pattern = class_pattern)) |>
pull(rn)
html_job_details <- html |> rvest::html_elements("body") |> rvest::html_elements("div") |> _[job_details_html_index]
return(html_job_details)
}
extract_top_card_html <- function(html_job_details, view = c("pane", "page")){
view <- match.arg(view, choices = c("pane", "page"), several.ok = F)
if(view == "pane"){
top_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(class == "jobs-unified-top-card__content--two-pane") |>
pull(rn)
html_top_card <- html_job_details |> rvest::html_elements("div") |> _[top_card_html_index]
} else if(view == "page"){
top_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(stringr::str_detect(class, "jobs-unified-top-card*.*artdeco-card")) |>
pull(rn)
html_top_card <- html_job_details |> rvest::html_elements("div") |> _[top_card_html_index]
}
return(html_top_card)
}
scrape_top_card_df <- function(html_top_card){
title <- html_top_card |> rvest::html_elements("div") |> rvest::html_text() |> str_squish() |> _[1]
subline <- html_top_card |> rvest::html_elements("div") |> rvest::html_text() |> str_squish() |> _[2]
company_name <- str_split_i(subline, pattern = "·", i = 1) |> str_squish()
location <- str_extract(subline, pattern = "([A-Z][a-z]+\\s?)+,\\s[A-Z]{2}")
workplace_type <- if_else(
str_detect(str_to_lower(subline), pattern = "remote"),
"remote",
if_else(
str_detect(str_to_lower(subline), pattern = "hybrid"),
"hybrid",
if_else(
str_detect(str_to_lower(subline), pattern = "on-site"),
"on-site",
"not provided")))
df_list_items <- tibble::tibble(
class = html_top_card |> html_element("ul") |> html_elements("li") |> html_attr("class"),
text = html_top_card |> html_element("ul") |> html_elements("li") |> html_text(),
icon_type = html_top_card |> html_element("ul") |> html_elements("li") |> html_element("li-icon") |> html_attr("type")
)
employment_type <- df_list_items |>
dplyr::filter(icon_type == "job") |>
dplyr::pull(text) |>
str_extract(pattern = "Full-time|Part-time|Contract|Volunteer|Temporary|Internship|Other")
job_level <- df_list_items |>
dplyr::filter(icon_type == "job") |>
dplyr::pull(text) |>
str_extract(pattern = "Internship|Entry Level|Associate|Mid-Senior level|Director|Executive")
company_size <- df_list_items |>
dplyr::filter(icon_type == "company") |>
dplyr::pull(text) |>
str_extract(pattern = "[0-9]{1,},?[0-9]*(-|\\+)([0-9]{1,},?[0-9]*)?")
company_industry <- df_list_items |>
dplyr::filter(icon_type == "company") |>
dplyr::pull(text) |>
str_split_i(pattern = "·", i = 2) |>
str_squish()
df_job_details <- tibble::tibble(
job_title = if_length0_NA_character(title),
job_level = if_length0_NA_character(job_level),
company_name = if_length0_NA_character(company_name),
company_industry = if_length0_NA_character(company_industry),
company_size = if_length0_NA_character(company_size),
location = if_length0_NA_character(location),
workplace_type = if_length0_NA_character(workplace_type),
employment_type = if_length0_NA_character(employment_type)
)
return(df_job_details)
}
extract_job_desc_card_html <- function(html_job_details){
job_desc_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(stringr::str_detect(class, "jobs-description-content")) |>
pull(rn)
html_job_desc_card <- html_job_details |> rvest::html_elements("div") |> rvest::html_elements("div") |> _[job_desc_card_html_index]
return(html_job_desc_card)
}
scrape_job_desc_df <- function(html_job_desc_card){
job_desc <- html_job_desc_card |> html_text() |> paste(collapse = (" ")) |> stringr::str_squish()
df_job_desc <- tibble::tibble(job_desc = job_desc)
return(df_job_desc)
}
extract_salary_card_html <- function(html_job_details){
salary_card_html_index <- tibble::tibble(id = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("id")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(id == "SALARY") |>
pull(rn)
html_salary_card <- html_job_details |> rvest::html_elements("div") |> _[salary_card_html_index]
return(html_salary_card)
}
scrape_salary_df <- function(html_salary_card){
salary_text_index <- html_salary_card |> rvest::html_elements("p") |> rvest::html_text() |> stringr::str_detect(pattern = "(from job description)|salary")
salary_text <- html_salary_card |> rvest::html_elements("p") |> rvest::html_text() |> _[salary_text_index] |> stringr::str_squish()
if(length(salary_text) != 0){
salary_interval <- str_extract_all(salary_text, pattern = "[1-9][0-9]?[0-9]?,?[0-9]?[0-9]?[0-9]?") |> purrr::map(str_remove, pattern = ",") |> purrr::map(as.double)
df_salary <- tibble(salary_min = min(unlist(salary_interval)), salary_max = max(unlist(salary_interval)))
} else {
df_salary <- tibble(salary_min = NA_real_, salary_max = NA_real_)
}
return(df_salary)
}
get_skills_open_button_id <- function(html_job_details){
skills_box_html_index <- tibble::tibble(
class = html_job_details |> html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(str_to_lower(class), pattern = "job-details-how-you-match-card__container")) |>
pull(rn)
html_skills_box <-html_job_details |> html_elements("div") |> _[skills_box_html_index]
button_id <- html_skills_box |> html_elements("button") |> html_attr("id")
return(button_id)
}
get_skills_close_button_id <- function(html_skills_modal){
html_x_button_index <- tibble::tibble(
aria_label = html_skills_modal |> html_elements("button") |> html_attr("aria-label"),
id = html_skills_modal |> html_elements("button") |> html_attr("id")
) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_to_lower(aria_label) == "dismiss") |>
pull(rn)
x_button_id <- html_skills_modal |> html_elements("button") |> html_attr("id") |> _[html_x_button_index]
}
extract_skills_modal_html <- function(html){
skills_modal_index <- tibble::tibble(
role = html |> rvest::html_elements("div") |> rvest::html_attr("role"),
class = html |> rvest::html_elements("div") |> rvest::html_attr("class")
) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(class, "job-details-skill-match-modal") & role == "dialog") |>
pull(rn)
html_skills_modal <- html |> rvest::html_elements("div") |> _[skills_modal_index]
return(html_skills_modal)
}
scrape_skills_chr <- function(html_skills_modal){
skills <- html_skills_modal |>
html_elements("li") |>
html_text() |>
str_squish() |>
str_remove(pattern = "Add$") |>
str_squish()
skills <- skills[skills != ""]
return(skills)
}
if_length0_NA_character <- function(var){
if(length(var) == 0){
x <- NA_character_
} else {
x <- var
}
return(x)
}
click_button <- function(driver, using = c("xpath", "css selector", "id", "name", "tag name", "class name", "link text", "partial link text"), value, nap_length = "short"){
url <- driver$client$getCurrentUrl()
click <- function(driver, using, value, nap_length){
driver$client$findElement(using = using, value = value)$getElementLocationInView()
driver$client$findElement(using = using, value = value)$clickElement()
nap_rnorm(nap_length)
message <- "Success"
return(message)
}
possibly_click <- possibly(insistently(click, rate = rate_backoff(pause_base = 5, pause_cap = 45, max_times = 3, jitter = T), quiet = FALSE), otherwise = url)
click_result <- possibly_click(driver = driver, using = using, value = value, nap_length = nap_length)
return(click_result)
}
nap_rnorm <- function(length = c("short", "moderate", "long")){
if(length[1] == "short"){
wait <- abs(rnorm(n = 1, mean = 1.25, sd = .25))
} else if(length[1] == "moderate"){
wait <- abs(rnorm(n = 1, mean = 3, sd = .5))
} else if(length[1] == "long") {
wait <- abs(rnorm(n = 1, mean = 6, sd = 1.5))
} else{
wait <- length
}
naptime::naptime(time = wait)
}
df_job_details <- scrape_job_details_df(driver)
glimpse(df_job_details)Rows: 1
Columns: 12
$ job_title <chr> "Data Analyst - Machine Learning"
$ job_level <chr> "Mid-Senior level"
$ company_name <chr> "AltaSource Group"
$ company_industry <chr> "IT Services and IT Consulting"
$ company_size <chr> "51-200"
$ location <chr> NA
$ workplace_type <chr> "remote"
$ employment_type <chr> "Contract"
$ job_desc <chr> "About the job Data Analyst - Machine Learning AltaSo…
$ salary_min <dbl> NA
$ salary_max <dbl> NA
$ skills <list> <"Data Analysis", "Data Mining", "Data Science", "Mac…All that code scraped details for one job, but we’ll want to do the same for all the jobs in df_jobs. We can create
df_jobs only has the jobs on the first page, which means we’ll have to navigate through all the pages of job lists if we want data for all the jobs returned by the search. In order to do that, we first need to figure out how many times we have to page - which we can find at the bottom of the jobs list page with the page numbers. We can use developer tools to find the HTML tags and attributes of those page numbers. The HTML tag is li (list), which is what the page numbers at the bottom are in. We can use a similar approach as before to scrape this list, and again, filter to the items that match what we want. This gives use a list of ID’s we can use to page through. That said, you might notice that we don’t have all the pages. That’s because the site only displays some pages, a …, and then the last page number. I used lag() from dplyr to find the ID that is the ellipsis because it doesn’t have a data-test-pagination-page-btn attribute. That makes it simple to keep that HTML id in my data frame so I can easily click on the ellipsis and continue paging rather than skipping over all the pages inside the ellipsis. I’ll still need to pull the HTML id’s for additional pages inside the ellipsis, but we can do that as we page through…
scrape_html <- function(driver){
html <- rvest::read_html(driver$client$getPageSource()[[1]])
return(html)
}
scrape_pages_df <- function(html){
df_pages <- tibble::tibble(
pagination_btn = html |> rvest::html_element("body") |> rvest::html_elements("li") |> rvest::html_attr("data-test-pagination-page-btn"),
id = html |> rvest::html_elements("body") |> rvest::html_elements("li") |> rvest::html_attr("id")
) |>
dplyr::mutate(pagination_btn = as.numeric(pagination_btn)) |>
dplyr::mutate(pagination_btn_ellipsis = lag(pagination_btn) +1) |>
dplyr::mutate(pagination_btn = coalesce(pagination_btn, pagination_btn_ellipsis), .keep = "unused") |>
dplyr::filter(stringr::str_detect(id, "ember") & !is.na(pagination_btn))
return(df_pages)
}
html <- scrape_html(driver)
df_pages <- scrape_pages_df(html)
pages <- seq.int(from = 1, to = max(df_pages$pagination_btn), by = 1)
print(pages) [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21We can use the info in df_page and walk() to click the next page button.
Selenium is now on page 2 at https://www.linkedin.com/jobs/search/?currentJobId=3640240357&f_WT=2%2C3&geoId=90000079&keywords=data%20analyst%20%7C%20data%20scientist&refresh=T&start=25
Selenium is now on page 3 at https://www.linkedin.com/jobs/search/?currentJobId=3612521369&f_WT=2%2C3&geoId=90000079&keywords=data%20analyst%20%7C%20data%20scientist&refresh=T&start=50
Selenium is now on page 4 at https://www.linkedin.com/jobs/search/?currentJobId=3674579573&f_WT=2%2C3&geoId=90000079&keywords=data%20analyst%20%7C%20data%20scientist&refresh=T&start=75If you’re still with me you’re a trooper. I put everything we’ve done so far in Selenium into functions so that I can run our scraper with a few function calls.
# Driver ####
open_driver <- function(port = 1443L, browser = "chrome", check = F, verbose = F){
driver <- rsDriver(port = port, browser = browser, check = check, verbose = F)
driver$client$maxWindowSize()
return(driver)
}
kill_driver <- function(driver){
driver$server$process$kill()
rm(driver, envir = rlang::global_env())
}
nap_rnorm <- function(length = c("short", "moderate", "long")){
if(length[1] == "short"){
wait <- abs(rnorm(n = 1, mean = 1.25, sd = .25))
} else if(length[1] == "moderate"){
wait <- abs(rnorm(n = 1, mean = 3, sd = .5))
} else if(length[1] == "long") {
wait <- abs(rnorm(n = 1, mean = 6, sd = 1.5))
} else{
wait <- length
}
naptime::naptime(time = wait)
}
# Interact ####
signin <- function(driver, session_key = Sys.getenv("LINKEDIN_UID"), session_password = Sys.getenv("LINKEDIN_PWD")){
url <- "https://www.linkedin.com/login?fromSignIn"
driver$client$navigate(url)
nap_rnorm("moderate")
driver$client$findElement("name", "session_key")$sendKeysToElement(list(session_key))
driver$client$findElement("name", "session_password")$sendKeysToElement(list(session_password))
driver$client$findElement("tag name", "BUTTON")$clickElement()
nap_rnorm("moderate")
message(glue::glue("Selenium is now at {driver$client$getCurrentUrl()}"))
}
minimize_messaging <- function(driver){
html <- scrape_html(driver)
aside_index <- html |> rvest::html_elements("aside") |> rvest::html_attr("class") |> stringr::str_detect(pattern = "msg-overlay") |> which()
html_aside <- html |> rvest::html_elements("aside") |> _[aside_index]
df_messaging <- tibble::tibble(
id = html_aside |> rvest::html_elements("button") |> rvest::html_attr("id"),
icon_type = html_aside |> rvest::html_elements("button") |> rvest::html_element("li-icon") |> rvest::html_attr("type")
) |>
dplyr::filter(icon_type == "chevron-down")
if(nrow(df_messaging) == 1){
id <- df_messaging$id
click_minimize <- function(driver, id){
driver$client$findElement("id", id)$clickElement()
return("Sucessefully minimized")
}
possibly_click_minimize <- possibly(click_minimize)
minimized <- possibly_click_minimize(driver = driver, id = id)
nap_rnorm("short")
}
}
search_jobs <- function(driver, keywords = NULL, date_posted = c("anytime", "month", "week", "24hrs"), workplace_types = c("on-site", "remote", "hybrid"), location = NULL, distance_mi = 5){
assertthat::assert_that(!is.null(keywords))
keywords = glue::glue("&keywords={keywords}")
date_posted <- get_datePosted(date_posted)
workplace_types <- get_workPlace_types(workplace_types)
if(!is.null(location)){
location <- glue::glue("&location={location}")
} else{
location <- ""
}
if(("on-site" %in% workplace_types | "hybrid" %in% workplace_types) & !is.null(distance_mi)){
distance <- glue::glue("&distance={distance_mi}")
} else{
distance <- ""
}
jobs_url <- URLencode(glue::glue("https://www.linkedin.com/jobs/search/?{date_posted}{workplace_types}{distance}{location}{keywords}&refresh=T"))
driver$client$navigate(jobs_url)
nap_rnorm("moderate")
message(glue::glue("Selenium is now at {jobs_url}"))
return(jobs_url)
}
get_datePosted <- function(arg){
choices <- c("anytime", "month", "week", "24hrs")
arg <- match.arg(arg, choices = choices, several.ok = F)
if(arg == "anytime"){
date_posted = ""
} else if(arg == "month"){
date_posted = "f_TPR=r604800"
} else if(arg == "week"){
date_posted = "f_TPR=r2592000"
} else if(arg == "24hrs"){
date_posted = "f_TPR=r86400"
} else {
message("Something went wrong with get_datePosted()")
}
return(date_posted)
}
get_workPlace_types <- function(args){
choices <- c("on-site", "remote", "hybrid")
args <- match.arg(args, choices = choices, several.ok = T)
args <- ifelse(args == "on-site"
, "1", ifelse(args == "remote", "2", ifelse(args == "hybrid", "3", NA_character_)))
args <- paste0("&f_WT=", paste(args, collapse = ","))
return(args)
}
scrollto_element <- function(driver, using = c("xpath", "css selector", "id", "name", "tag name", "class name", "link text", "partial link text"), value, nap_length = "short"){
html <- scrape_html(driver)
df_pages <- scrape_pages_df(html)
scrollto <- function(driver, using, value, nap_length){
webElem <- driver$client$findElement(using, value)
webElem$getElementLocationInView()
nap_rnorm(nap_length)
return("Success")
}
possibly_scrollto <- possibly(insistently(scrollto, rate = rate_backoff(pause_base = 5, pause_cap = 45, max_times = 3, jitter = T), quiet = FALSE), otherwise = "Fail")
scrollto_result <- possibly_scrollto(driver = driver, using = using, value = value, nap_length = nap_length)
return(scrollto_result)
}
scrollto_paging <- function(driver){
html <- scrape_html(driver)
df_pages <- scrape_pages_df(html)
scrollto_element(driver, "id", df_pages$id[1])
}
load_jobs_list <- function(driver, n_jobs = 0){
if(n_jobs == 0){
scrollto_paging(driver)
}
df_jobs_list <- scrape_jobs_list_df(driver)
if(n_jobs < nrow(df_jobs_list)){
randwalk_jobs(driver, df_jobs_list$id)
load_jobs_list(driver, n_jobs = nrow(df_jobs_list))
} else {
message(glue::glue("Loaded {n_jobs} jobs"))
}
}
randwalk_jobs <- function(driver, ids){
ids <- ids |>
sort() |>
sample()
purrr::walk(ids, function(id){
scrollto_element(driver, "id", id, nap_length = .25)
})
}
click_button <- function(driver, using = c("xpath", "css selector", "id", "name", "tag name", "class name", "link text", "partial link text"), value, nap_length = "short"){
url <- driver$client$getCurrentUrl()
click <- function(driver, using, value, nap_length){
driver$client$findElement(using = using, value = value)$getElementLocationInView()
driver$client$findElement(using = using, value = value)$clickElement()
nap_rnorm(nap_length)
message <- "Success"
return(message)
}
possibly_click <- possibly(insistently(click, rate = rate_backoff(pause_base = 5, pause_cap = 45, max_times = 3, jitter = T), quiet = FALSE), otherwise = url)
click_result <- possibly_click(driver = driver, using = using, value = value, nap_length = nap_length)
return(click_result)
}
# Scrape ####
scrape_html <- function(driver){
html <- rvest::read_html(driver$client$getPageSource()[[1]])
return(html)
}
if_length0_NA_character <- function(var){
if(length(var) == 0){
x <- NA_character_
} else {
x <- var
}
return(x)
}
scrape_pages_df <- function(html){
df_pages <- tibble::tibble(
pagination_btn = html |> rvest::html_element("body") |> rvest::html_elements("li") |> rvest::html_attr("data-test-pagination-page-btn"),
id = html |> rvest::html_elements("body") |> rvest::html_elements("li") |> rvest::html_attr("id")
) |>
dplyr::mutate(pagination_btn = as.numeric(pagination_btn)) |>
dplyr::mutate(pagination_btn_ellipsis = lag(pagination_btn) +1) |>
dplyr::mutate(pagination_btn = coalesce(pagination_btn, pagination_btn_ellipsis), .keep = "unused") |>
dplyr::filter(stringr::str_detect(id, "ember") & !is.na(pagination_btn))
return(df_pages)
}
scrape_jobs_list_df <- function(driver){
html <- scrape_html(driver = driver)
job_li_ids <- get_li_ids(html) |> remove_blank_ids()
df_jobs_list <- purrr::map(job_li_ids, function(li_id){
li_index <- which(get_li_ids(html) == li_id)
li_element <- get_li_elements(html, li_index)
id <- li_element |> rvest::html_elements("a") |> rvest::html_attr("id")
class <- li_element |> rvest::html_elements("a") |> rvest::html_attr("class")
href <- li_element |> rvest::html_elements("a") |> rvest::html_attr("href")
url <- paste0("https://www.linkedin.com/", href)
img <- li_element |> rvest::html_element("div") |>rvest::html_element("img") |> rvest::html_attr("src")
alt <- li_element |> rvest::html_elements("img") |> rvest::html_attr("alt") |> stringr::str_squish() |> _[1]
text <- li_element |> rvest::html_elements("a") |> rvest::html_text() |> stringr::str_squish()
tibble::tibble(
li_id = li_id,
id = id,
class = class,
url = url,
img = img,
alt = alt,
text = text,
)
}) |>
purrr::list_rbind() |>
dplyr::filter(stringr::str_detect(url, pattern = "/jobs/view/")) |>
dplyr::filter(stringr::str_detect(class, pattern = "job-card-list__title"))
return(df_jobs_list)
}
get_li_ids <- function(html){
li_ids <- html |> rvest::html_element("main") |> rvest::html_element("ul") |> rvest::html_elements("li") |> rvest::html_attr("id")
return(li_ids)
}
remove_blank_ids <- function(ids){
keep_ids <- ids[!is.na(ids)]
return(keep_ids)
}
get_li_elements <- function(html, index){
li_elements <- html |> rvest::html_element("main") |> rvest::html_element("ul") |> rvest::html_elements("li")
li_element <- li_elements[index]
return(li_element)
}
scrape_job_details_df <- function(driver, id = NULL, view = c("pane", "page")){
html <- scrape_html(driver)
html_job_details <- extract_job_details_html(html, view)
html_top_card <- extract_top_card_html(html_job_details, view)
df_job_details <- scrape_top_card_df(html_top_card)
html_job_desc_card <- extract_job_desc_card_html(html_job_details)
df_job_desc <- scrape_job_desc_df(html_job_desc_card)
df_job_details <- dplyr::bind_cols(df_job_details, df_job_desc)
html_salary_card <- extract_salary_card_html(html_job_details)
df_job_details <- dplyr::bind_cols(
df_job_details,
scrape_salary_df(html_salary_card))
open_skills_button_id <- get_skills_open_button_id(html_job_details)
open_skills_click_result <- click_button(driver, "id", open_skills_button_id, nap_length = "long")
if(open_skills_click_result == "Success"){
html <- scrape_html(driver)
html_skills_modal <- extract_skills_modal_html(html)
close_skills_button_id <- get_skills_close_button_id(html_skills_modal)
close_skills_click_result <- click_button(driver, "id", close_skills_button_id, nap_length = "short")
if(close_skills_click_result != "Success"){driver$client$goBack()}
skills <- scrape_skills_chr(html_skills_modal)
df_job_details$skills <- list(skills)
} else {
skills <- NA_character_
df_job_details$skills <- list(skills)
}
df_job_details$id <- id
return(df_job_details)
}
extract_job_details_html <- function(html, view = c("pane", "page")){
view <- match.arg(view, choices = c("pane", "page"), several.ok = F)
if(view == "pane"){
class_pattern <- "scaffold-layout__detail"
} else if(view == "page"){
class_pattern <- "job-view-layout jobs-details"
} else{
class_pattern <- "jobs-details"
}
job_details_html_index <- tibble::tibble(class = html |> rvest::html_elements("body") |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(class, pattern = class_pattern)) |>
pull(rn)
html_job_details <- html |> rvest::html_elements("body") |> rvest::html_elements("div") |> _[job_details_html_index]
return(html_job_details)
}
extract_top_card_html <- function(html_job_details, view = c("pane", "page")){
view <- match.arg(view, choices = c("pane", "page"), several.ok = F)
if(view == "pane"){
top_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(class == "jobs-unified-top-card__content--two-pane") |>
pull(rn)
html_top_card <- html_job_details |> rvest::html_elements("div") |> _[top_card_html_index]
} else if(view == "page"){
top_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(stringr::str_detect(class, "jobs-unified-top-card*.*artdeco-card")) |>
pull(rn)
html_top_card <- html_job_details |> rvest::html_elements("div") |> _[top_card_html_index]
}
return(html_top_card)
}
scrape_top_card_df <- function(html_top_card){
title <- html_top_card |> rvest::html_elements("div") |> rvest::html_text() |> str_squish() |> _[1]
subline <- html_top_card |> rvest::html_elements("div") |> rvest::html_text() |> str_squish() |> _[2]
company_name <- str_split_i(subline, pattern = "·", i = 1) |> str_squish()
location <- str_extract(subline, pattern = "([A-Z][a-z]+\\s?)+,\\s[A-Z]{2}")
workplace_type <- if_else(
str_detect(str_to_lower(subline), pattern = "remote"),
"remote",
if_else(
str_detect(str_to_lower(subline), pattern = "hybrid"),
"hybrid",
if_else(
str_detect(str_to_lower(subline), pattern = "on-site"),
"on-site",
"not provided")))
df_list_items <- tibble::tibble(
class = html_top_card |> html_element("ul") |> html_elements("li") |> html_attr("class"),
text = html_top_card |> html_element("ul") |> html_elements("li") |> html_text(),
icon_type = html_top_card |> html_element("ul") |> html_elements("li") |> html_element("li-icon") |> html_attr("type")
)
employment_type <- df_list_items |>
dplyr::filter(icon_type == "job") |>
dplyr::pull(text) |>
str_extract(pattern = "Full-time|Part-time|Contract|Volunteer|Temporary|Internship|Other")
job_level <- df_list_items |>
dplyr::filter(icon_type == "job") |>
dplyr::pull(text) |>
str_extract(pattern = "Internship|Entry Level|Associate|Mid-Senior level|Director|Executive")
company_size <- df_list_items |>
dplyr::filter(icon_type == "company") |>
dplyr::pull(text) |>
str_extract(pattern = "[0-9]{1,},?[0-9]*(-|\\+)([0-9]{1,},?[0-9]*)?")
company_industry <- df_list_items |>
dplyr::filter(icon_type == "company") |>
dplyr::pull(text) |>
str_split_i(pattern = "·", i = 2) |>
str_squish()
df_job_details <- tibble::tibble(
job_title = if_length0_NA_character(title),
job_level = if_length0_NA_character(job_level),
company_name = if_length0_NA_character(company_name),
company_industry = if_length0_NA_character(company_industry),
company_size = if_length0_NA_character(company_size),
location = if_length0_NA_character(location),
workplace_type = if_length0_NA_character(workplace_type),
employment_type = if_length0_NA_character(employment_type)
)
return(df_job_details)
}
extract_job_desc_card_html <- function(html_job_details){
job_desc_card_html_index <- tibble::tibble(class = html_job_details |> rvest::html_elements("div") |> rvest::html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(stringr::str_detect(class, "jobs-description-content")) |>
pull(rn)
html_job_desc_card <- html_job_details |> rvest::html_elements("div") |> rvest::html_elements("div") |> _[job_desc_card_html_index]
return(html_job_desc_card)
}
scrape_job_desc_df <- function(html_job_desc_card){
job_desc <- html_job_desc_card |> html_text() |> paste(collapse = (" ")) |> stringr::str_squish()
df_job_desc <- tibble::tibble(job_desc = job_desc)
return(df_job_desc)
}
extract_salary_card_html <- function(html_job_details){
salary_card_html_index <- tibble::tibble(id = html_job_details |> rvest::html_elements("div") |> rvest::html_attr("id")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(id == "SALARY") |>
pull(rn)
html_salary_card <- html_job_details |> rvest::html_elements("div") |> _[salary_card_html_index]
return(html_salary_card)
}
scrape_salary_df <- function(html_salary_card){
salary_text_index <- html_salary_card |> rvest::html_elements("p") |> rvest::html_text() |> stringr::str_detect(pattern = "(from job description)|salary")
salary_text <- html_salary_card |> rvest::html_elements("p") |> rvest::html_text() |> _[salary_text_index] |> stringr::str_squish()
if(length(salary_text) != 0){
salary_interval <- str_extract_all(salary_text, pattern = "[1-9][0-9]?[0-9]?,?[0-9]?[0-9]?[0-9]?") |> purrr::map(str_remove, pattern = ",") |> purrr::map(as.double)
df_salary <- tibble(salary_min = min(unlist(salary_interval)), salary_max = max(unlist(salary_interval)))
} else {
df_salary <- tibble(salary_min = NA_real_, salary_max = NA_real_)
}
return(df_salary)
}
get_skills_open_button_id <- function(html_job_details){
skills_box_html_index <- tibble::tibble(
class = html_job_details |> html_elements("div") |> rvest::html_attr("class")) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(str_to_lower(class), pattern = "job-details-how-you-match-card__container")) |>
pull(rn)
html_skills_box <-html_job_details |> html_elements("div") |> _[skills_box_html_index]
button_id <- html_skills_box |> html_elements("button") |> html_attr("id")
return(button_id)
}
get_skills_close_button_id <- function(html_skills_modal){
html_x_button_index <- tibble::tibble(
aria_label = html_skills_modal |> html_elements("button") |> html_attr("aria-label"),
id = html_skills_modal |> html_elements("button") |> html_attr("id")
) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_to_lower(aria_label) == "dismiss") |>
pull(rn)
x_button_id <- html_skills_modal |> html_elements("button") |> html_attr("id") |> _[html_x_button_index]
}
extract_skills_modal_html <- function(html){
skills_modal_index <- tibble::tibble(
role = html |> rvest::html_elements("div") |> rvest::html_attr("role"),
class = html |> rvest::html_elements("div") |> rvest::html_attr("class")
) |>
dplyr::mutate(rn = dplyr::row_number()) |>
filter(str_detect(class, "job-details-skill-match-modal") & role == "dialog") |>
pull(rn)
html_skills_modal <- html |> rvest::html_elements("div") |> _[skills_modal_index]
return(html_skills_modal)
}
scrape_skills_chr <- function(html_skills_modal){
skills <- html_skills_modal |>
html_elements("li") |>
html_text() |>
str_squish() |>
str_remove(pattern = "Add$") |>
str_squish()
skills <- skills[skills != ""]
return(skills)
}
scrape_jobs_df <- function(driver){
load_jobs_list(driver)
df_job_list <- scrape_jobs_list_df(driver)
df_job_details <- map(df_job_list$id, function(id){
click_job_result <- click_button(driver, "id", id, nap_length = "moderate")
if(click_job_result == "Success"){
df_job_details <- scrape_job_details_df(driver, id, view = "pane")
} else {
df_job_details <- get_df_job_details_schema(id = id)
}
return(df_job_details)
}) |> bind_rows()
df_jobs <- dplyr::left_join(df_job_list, df_job_details, by = c("id" = "id"))
details_cols <- get_df_job_details_schema() |> select(-id) |> names()
filter_blank_details <- . %>%
dplyr::filter(dplyr::if_all(.cols = details_cols, ~is.na(.)))
remove_details_columns <- . %>%
select(-tidyselect::all_of(details_cols))
df_missing_details <- df_jobs |>
filter_blank_details() |>
remove_details_columns()
if(nrow(df_missing_details)>0){
df_jobs <- df_jobs |> filter(id %in% df_missing_details$id)
df_retry_details <-purrr::map2(df_missing_details$id, df_missing_details$url, function(id, url){
click_job_result <- click_button(driver, "id", id, nap_length = "moderate")
driver$client$navigate(url)
nap_rnorm("long")
df_retry <- scrape_job_details_df(driver, id = id, view = "page")
return(df_retry)
})
df_missing_details <- dplyr::left_join(df_missing_details, df_retry_details, by = c("id" = "id"))
df_jobs <- dplyr::bind_rows(df_jobs, df_missing_details)
}
return(df_jobs)
}
scrape_job_search <- function(driver, page_cap = NULL){
df_pages <- scrape_pages_df(scrape_html(driver))
pages <- seq.int(from = 1, to = min(max(df_pages$pagination_btn), page_cap), by = 1)
message(glue::glue("Preparing to scrape {max(pages)} pages..."))
df_job_search <- purrr::map(pages, function(i){
df_jobs <- scrape_jobs_df(driver)
df_pages <- scrape_pages_df(scrape_html(driver)) |> dplyr::filter(pagination_btn == i + 1)
if(nrow(df_pages) == 1){
page_click_result <- click_button(driver, "id", df_pages$id, nap_length = "long")
if(page_click_result == "Success"){
message(glue::glue("Selenium is now on page {df_pages$pagination_btn} at {driver$client$getCurrentUrl()}"))
} else {
next_page_url <- modify_job_search_url_page_n(driver, n = i + 1)
driver$client$navigate(next_page_url)
message(glue::glue("scrape_pages_df() did not get a matching page, using alternative navigation to go to page {i + 1} at {driver$client$getCurrentUrl()}"))
}
} else{
message("Done")
}
return(df_jobs)
}) |> dplyr::bind_rows()
return(df_job_search)
}
# Utils ####
get_df_job_details_schema <- function(id = ""){
tibble::tibble(
job_title = NA_character_,
job_level = NA_character_,
company_name = NA_character_,
company_industry = NA_character_,
company_size = NA_character_,
location = NA_character_,
workplace_type = NA_character_,
employment_type = NA_character_,
salary_min = NA_character_,
salary_max = NA_character_,
skills = NA_character_,
id = id
)
}
get_job_search_page_n <- function(driver){
n <- as.numeric(stringr::str_remove(stringr::str_extract(driver$client$getCurrentUrl(), "start=[1-9][0-9][0-9]?[0-9]?[0-9]?"), "start=")) / 25
return(n)
}
modify_job_search_url_page_n <- function(driver, n = 1){
if(n <= 1){
start <- 1
} else {
start <- n * 25 - 25
}
url <- stringr::str_remove(driver$client$getCurrentUrl(), "&start=[1-9][0-9][0-9]?[0-9]?[0-9]?")
url <- glue::glue("{url}&start={start}")
return(url)
}
kill_driver(driver)Which we can test out for a few pages of jobs with the script below to get all the data in one data frame 😎
Rows: 50
Columns: 19
$ li_id <chr> "ember222", "ember235", "ember247", "ember260", "embe…
$ id <chr> "ember228", "ember241", "ember253", "ember266", "embe…
$ class <chr> "disabled ember-view job-card-container__link job-car…
$ url <chr> "https://www.linkedin.com//jobs/view/3673567890/?eBP=…
$ img <chr> "https://media.licdn.com/dms/image/C560BAQEKdbNtIQcvy…
$ alt <chr> "innoVet Health (SDVOSB) logo", "TRM Labs logo", "Wha…
$ text <chr> "Senior Data Scientist", "Senior Data Scientist", "Se…
$ job_title <chr> "Senior Data Scientist", "Senior Data Scientist", "Se…
$ job_level <chr> NA, "Mid-Senior level", "Mid-Senior level", "Mid-Seni…
$ company_name <chr> "innoVet Health (SDVOSB)", "TRM Labs", "Whatnot", "Li…
$ company_industry <chr> NA, "Information Services", "Technology, Information …
$ company_size <chr> "11-50", "51-200", "201-500", "51-200", "51-200", "11…
$ location <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, "Seattle, WA"…
$ workplace_type <chr> "remote", "remote", "remote", "remote", "remote", "re…
$ employment_type <chr> "Full-time", "Full-time", "Full-time", "Full-time", "…
$ job_desc <chr> "About the job InnoVet Health, a small and growing bu…
$ salary_min <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 157500, 144000, 88, 1…
$ salary_max <dbl> NA, NA, NA, NA, NA, NA, NA, NA, 205000, 157000, 98, 1…
$ skills <list> <"Data Analysis", "Data Analytics", "Data Science", …Screen scraping is a labor of love, but it can be a valuable data collection tool in certain cases. There are a few R packages to know when screen scraping including rvest, RSelenium, polite, and indirectly purrr. I hope this post is a helpful guide for others in the future, please don’t hesitate to reach out if you have any questions or feedback!